Over de auteur
Peter ter Braake is zelfstandig SQL Server docent/consultant. Hij is MCT sinds 2002 en
SQL Server MVP sinds begin 2012. Hij werkt met SQL Server Reporting Services sinds de
eerste release in 2004.
978 90 395 2721 4
123
9 *uklpdo#bxmxyv*
Aan de slag met Reporting Services 2012
Ook alle instellingen die u kunt kiezen
voor rapporten nadat ze in gebruik zijn
gekomen, komen aan de orde.
Dankzij de opgaven biedt het boek
voldoende mogelijkheden om te oefenen
en ervaring op te doen. Zo kunt u de
behandelde stof direct in de praktijk
toepassen.
Aan de slag met Reporting Services 2012 is
bedoeld voor studenten en professionals
die met Reporting Services gaan werken.
Voorkennis van Reporting Services is
niet noodzakelijk, maar kennis van het
Microsoft-platform is een pre. Daarnaast
is het in de praktijk onontbeerlijk om enige
kennis te hebben van SQL of als u met
kubussen wilt werken, van MDX.
ter Braake Microsoft SQL Server 2012 Reporting
Services is een uitgebreide tool om
rapporten mee te maken, te beheren en te
gebruiken. Het biedt vele mogelijkheden
en opties en is bruikbaar in zowel de
kleinste, alsook de grootste en meest
kritische omgevingen.
De beste manier om een uitgebreid
product zoals Reporting Services te leren
kennen is er actief mee te werken. Dit
boek is geschreven om u daarbij te helpen.
Stap voor stap wordt u begeleid bij het
installeren van Reporting Services en
vervolgens bij het maken van rapporten.
Bij alle keuzes wordt stilgestaan bij de
mogelijke opties en wanneer te kiezen
voor welke optie. Zo leert u al doende
goede en duidelijk rapporten te bouwen
en ze te gebruiken.
Aan de slag met
Reporting Services 2012
voor Microsoft SQL Server
Peter ter Braake
Aan de slag met
Reporting Services 2012
voor Microsoft SQL Server
Peter ter Braake
Meer informatie over deze en andere uitgaven kunt u verkrijgen bij:
Sdu Klantenservice
Postbus 20014
2500 EA Den Haag
tel.: (070) 378 98 80
www.sdu.nl/service
© 2013 Sdu Uitgevers, Den Haag
Academic Service is een imprint van Sdu Uitgevers bv.
Zetwerk: Redactiebureau Ron Heijer, Markelo
Omslagontwerp: Studio Bassa, Culemborg
Omslaguitvoering: Carlito’s Design, Amsterdam
ISBN 978 90 395 2721 4
NUR 123 / 995
Alle rechten voorbehouden. Alle intellectuele eigendomsrechten, zoals auteurs- en databankrechten, ten
aanzien van deze uitgave worden uitdrukkelijk voorbehouden. Deze rechten berusten bij Sdu Uitgevers bv en
de auteur.
Behoudens de in of krachtens de Auteurswet gestelde uitzonderingen, mag niets uit deze uitgave worden
verveelvoudigd, opgeslagen in een geautomatiseerd gegevensbestand of openbaar gemaakt in enige vorm of
op enige wijze, hetzij elektronisch, mechanisch, door fotokopieën, opnamen of enige andere manier, zonder
voorafgaande schriftelijke toestemming van de uitgever.
Voor zover het maken van reprografische verveelvoudigingen uit deze uitgave is toegestaan op grond van artikel 16 h Auteurswet, dient men de daarvoor wettelijk verschuldigde vergoedingen te voldoen aan de Stichting
Reprorecht (Postbus 3051, 2130 KB Hoofddorp, www.reprorecht.nl). Voor het overnemen van gedeelte(n) uit
deze uitgave in bloemlezingen, readers en andere compilatiewerken (artikel 16 Auteurswet) dient men zich te
wenden tot de Stichting PRO (Stichting Publicatie- en Reproductierechten Organisatie, Postbus 3060, 2130 KB
Hoofddorp, www.cedar.nl/pro). Voor het overnemen van een gedeelte van deze uitgave ten behoeve van commerciële doeleinden dient men zich te wenden tot de uitgever.
Hoewel aan de totstandkoming van deze uitgave de uiterste zorg is besteed, kan voor de afwezigheid van
eventuele (druk)fouten en onvolledigheden niet worden ingestaan en aanvaarden de auteur(s), redacteur(en)
en uitgever deswege geen aansprakelijkheid voor de gevolgen van eventueel voorkomende fouten en onvolledigheden.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without the
publisher’s prior consent.
While every effort has been made to ensure the reliability of the information presented in this publication, Sdu
Uitgevers neither guarantees the accuracy of the data contained herein nor accepts responsibility for errors or
omissions or their consequences.
Voorwoord
Voor u ligt een boek over Microsoft SQL Server 2012 Reporting Services. Reporting
Services is een uitgebreide tool om rapporten mee te maken, te beheren en te gebruiken. Het biedt vele mogelijkheden en opties en is bruikbaar in zowel de kleinste,
alsook de grootste en meest kritische omgevingen. Afhankelijk van uw situatie wilt u
meer of minder van de mogelijkheden benutten.
De beste manier om een uitgebreid product zoals Reporting Services te leren kennen
is er actief mee te werken. Dit boek is geschreven om u daarbij te helpen. Stap voor
stap wordt u begeleid bij het installeren van Reporting Services en vervolgens bij het
maken van rapporten. Bij alle keuzes wordt stilgestaan bij de mogelijke opties en
wanneer te kiezen voor welke optie. Zo leert u al doende mooie rapporten te bouwen
en ze te gebruiken. Ook alle instellingen die u kunt kiezen voor rapporten nadat ze in
gebruik zijn gekomen, komen aan de orde.
Dit boek bevat opgaven om al het geleerde ook in de praktijk toe te passen. Zoals
gezegd is doen belangrijk om met Reporting Services te leren werken. Middels de
opgaven kunt u de nodige ervaring opdoen.
Dit boek gaat niet uit van enige voorkennis. Het is bedoeld voor studenten en professionals die nu of in de toekomst met Reporting Services gaan werken. Tegelijkertijd is
kennis van het Microsoft-platform een pre. Daarnaast is het in de praktijk onontbeerlijk om enige kennis te hebben van SQL (Structured Query Language) of MDX (Multi
Dimensional eXpressions) als u met kubussen gaat werken.
Dit boek was niet tot stand gekomen zonder het begrip van mijn vrouw. Ook wil ik
Bert Brummelhuis en Albert van Dok bedanken voor hun input.
Veel plezier met Reporting Services!
Peter ter Braake
Bunnik, januari 2013
v
Inhoud
Voorwoord
v
1
Inleiding informatiemanagement
1.1 Inleiding Business Intelligence
1.1.1 De relationele database
1.1.2 Business Intelligence
1.2 Het datawarehouse
1.3 Het stermodel
1.4 Soorten beslissingen
1.5 Soorten rapporten
1.6OLAP-kubus
1.6.1 Voordelen van kubussen
1.6.2 Tabular Model
1.7 Ontstaan SQL Server Reporting Services
1.8 Tot slot
1
1
1
2
4
5
8
10
12
13
15
15
17
2
Inleiding Microsoft SQL Server Reporting Services
2.1 Wat is SQL Server Reporting Services?
2.2 SQL Server-edities
2.3 Installeren van Reporting Services
2.4 Stand-alone installatie
2.4.1Controle
2.5 Configureren van stand-alone Reporting Services
2.5.1 Configureren van de ReportServer-database
2.5.2 Configureren van de Web Service
2.5.3 Overige instellingen
2.5.4 Tot slot
2.6 SharePoint integrated mode
2.7 Configureren voor SharePoint integrated mode
2.7.1 Reporting Services-service toevoegen aan SharePoint
2.7.2 Reporting Services Service Application
2.8 Activeren Power View
2.9 Installeren van PowerPivot voor SharePoint
2.9.1 PowerPivot Gallery aanmaken
2.9.2 BI Semantic Model Connection
2.10 Downloaden en installeren Report Builder 3.0
2.11 Tot slot
19
19
20
22
23
26
27
28
30
32
33
34
35
36
36
38
38
39
39
39
41
vii
Aan de slag met Reporting Services 2012
viii
3
Eenvoudige rapporten maken
3.1Projecten
3.1.1 Shared Data Sources
3.1.2 Shared Datasets
3.2 Het eerste rapport
3.2.1 Data Source
3.2.2Dataset
3.2.3 Text, Table of Stored Procedure?
3.2.4 Data Regions
3.2.5 Basale opmaak
3.2.6 Headers en footers
3.2.7 Conditionele opmaak en afwisselende achtergrond
3.2.8 Sortering en herhalingen
3.2.9Groepen
3.2.10 Berekende velden
3.3 Report Builder
3.3.1 Maken van een rapport
3.4 Tot slot
4
Interactieve rapporten en Data Regions
4.1 Rapporten met parameters
4.1.1Queryparameters
4.1.2 Parameter Properties
4.1.3 Gekoppelde parameters
4.1.4 Filteren op gebruikersnaam
4.1.5 Multiple Values
4.1.6Filters
4.2 Interactieve rapporten
4.2.1 Document Map
4.2.2Drill-down
4.2.3Action
4.3 Data Regions: List, Chart en Matrix
4.3.1Templates
4.3.2List
4.3.3Chart
4.3.4 Matrix- en subrapporten
4.3.5 Drill-through naar Stamkaart
4.4 Meer visualisaties
4.4.1Sparkline
4.4.2 Data Bar
4.4.3 Indicators en Gauges
4.5Pagina-instellingen
4.5.1 Page size en Interactive page size
4.6 Gegevens uit SQL Server Analysis Services
4.6.1 Gegevens uit een kubus
4.6.2 Gegevens uit een Tabular Model
4.7 Tot slot
43
43
45
47
49
50
51
53
57
59
64
68
70
72
75
79
80
81
83
83
84
85
87
89
90
92
95
96
97
100
101
102
103
105
107
108
109
110
111
112
115
115
116
116
118
118
Inhoud
5
Beheer van Reporting Services
5.1 In gebruik nemen van rapporten
5.1.1Projectinstellingen
5.1.2 Publiceren vanuit SQL Server Data Tools
5.1.3 Andere opties
5.1.4 Tot slot
5.2Rapportinstellingen
5.2.1 De rapport Data Source
5.2.2Caching
5.2.3Snapshots
5.2.4 Report History
5.2.5Rapporttime-outs
5.2.6Parameters
5.2.7 Linked Reports
5.3Subscriptions
5.3.1 Standard Subscriptions
5.3.2 Data-driven Subscriptions
5.4Security
5.4.1 Role-based Security in native mode
5.4.2 Rechten in SharePoint
5.5 Data Alerts
5.6 Tot slot
119
119
119
121
122
123
123
123
127
130
132
133
133
134
135
135
138
140
141
142
143
144
6
PowerPivot en Tabular Models
6.1Inleiding
6.1.1 Wie maakt BI-oplossingen?
6.1.2 Selfservice BI
6.2PowerPivot
6.2.1 Downloaden en installeren
6.2.2 Een PowerPivot-werkmap maken
6.2.3 Een PowerPivot-rapport maken in Excel
6.2.4 Het model verbeteren
6.2.5 Nieuwe kolommen maken
6.2.6Sorteren
6.2.7Hiërarchieën
6.2.8 Relaties maken
6.2.9 Tot slot
6.3 Business Intelligence Tabular Model
6.3.1 Tabular Models versus Multidimensional Models
6.3.2 Een Tabular Model maken met SQL Server Data Tools
6.3.3 Analyze in Excel
6.3.4 Berekende waarden toevoegen
6.3.5 Tijdintelligentie toevoegen
6.3.6 Instellingen voor rapportages
6.3.7 KPI’s maken
6.3.8Perspectives
145
145
145
147
148
148
148
151
153
154
156
157
159
160
160
160
161
163
164
165
166
169
170
ix
Aan de slag met Reporting Services 2012
7
x
6.3.9 PowerPivot versus Tabular Model
6.3.10 Publiceren van het model
6.4 Tot slot
171
173
173
Power View
7.1 Connecties maken
7.2 Het eerste Power View-rapport
7.3 Rapporten bekijken en highlighting
7.3.1 Opslaan van een rapport
7.3.2 Exporteren naar PowerPoint
7.4 Filters en Slicers
7.4.1Filters
7.4.2Slicers
7.5 Views, Tiles en Cards
7.5.1Views
7.5.2Tiles
7.5.3Cards
7.6 Bubble en Scatter Charts
7.6.1 Scatter Charts
7.6.2 Bubble Charts
7.6.3 Extra opties
7.7 Tot slot
175
175
177
180
182
182
182
182
183
185
185
185
186
187
188
188
188
189
Opgaven
Opgaven bij Hoofdstuk 3 en 4 – Creating Reports
Opgave 1 – Territory Sales Drilldown
Opgave 2 –Sales Order Detail
Extra opgaven bij Hoofdstuk 3 en 4 – Report Builder 3.0
Opgave 3 – Publish Report Parts
Opgave 4 – Report Builder 3.0
Opgave 5 – Aanpassingen maken aan het rapport
Opgaven bij Hoofdstuk 5 – Reporting Management
Opgave 6 – Deploying en Linked Reports
Opgave 7 – Scheduling
Opgave 8 – Monitoring
Opgave 9 – Caching en Snapshots
Opgave 10 – Security
Opgaven bij Hoofdstuk 6 – Tabular Model Opgave 11 – PowerPivot
Opgave 12 – Maak een Excel-rapportage
Opgave 13 – Maak SSAS Tabular Model
Opgave 14 – Deploy en gebruik van Tabular Model
Opgave 15 – Extra
Opgaven bij Hoofdstuk 7 – Power View
Opgave 16 – Power View-visualisaties maken
191
191
191
195
196
196
198
199
199
199
200
200
201
202
202
202
204
206
209
210
210
210
213
Index
Hoofdstuk 1
Inleiding informatiemanagement
Met Reporting Services en de bijbehorende tools kunt u rapporten maken, in productie nemen en beheren. In dit boek gaat u over al die facetten leren. Voordat u daar in
Hoofdstuk 2 echt mee begint, is het goed om eerst een kader te scheppen. Waarvoor is
een tool zoals Reporting Services bedoeld en waar komt Reporting Services vandaan?
Beide vragen worden beantwoord in dit eerste hoofdstuk.
1.1
Inleiding Business Intelligence
Mensen hebben binnen bedrijven altijd al met informatie gewerkt. Als u in het kader
van uw werk een beslissing moet nemen, wilt u die het liefst baseren op kennis en op
feiten. U heeft dus informatie nodig. Rapporten bieden als het goed is die informatie.
Daarom zijn rapporten onmisbaar in het bedrijfsleven.
Met de opkomst van de computer kwam die informatie in databases terecht. Samen
met de opkomst van databases ontstond de behoefte om rapportages te maken op basis
van de gegevens in die databases. Iedereen wil weten wat er hier en nu speelt binnen
het bedrijf. En veel van wat er te weten is, zit in de database.
1.1.1
De relationele database
Begin jaren zeventig van de vorige eeuw ontwikkelde Edgar F. Codd van IBM de relationele database. Marketingverhalen over de eerste relationele databases uit die tijd
vertellen ons dat het real-time voor handen hebben van informatie via rapportages de
meerwaarde van (relationele) databases is. Als gegevens handmatig uit dossiermappen
gehaald moeten worden en overgeschreven moeten worden op een rapportage, zult u
waarschijnlijk minder informatie, op een later moment krijgen.
OLTP versus OLAP
Uit die tijd komen ook de termen OLTP en OLAP. OLTP staat voor Online Transaction
Processing en OLAP betekent Online Analytical Processing. In beide gevallen heeft
online hier niets te maken met het internet (dat bestond toen nog niet). Het refereert
aan het feit dat we tijdens het werken live een connectie hebben met de database. Dus
krijgt de gebruiker direct het antwoord op de vraag die hij/zij stelt.
Naast het online werken met de database werd de relationele database hand in hand
ontworpen met SQL, oftewel Structured Query Language. In eerste instantie was de
beoogde naam van die taal zelfs English Query Language, wat de ambitie goed weergeeft. SQL zou ons in staat moeten stellen om in het Engels (of zo dicht als mogelijk
bij het Engels) een vraag te formuleren en er dan real-time antwoord op te krijgen.
Kortom, precies wat we willen.
1
Aan de slag met Reporting Services 2012
1.1.2
Business Intelligence
Tegenwoordig is Business Intelligence een groot vakgebied waarin bedrijven veel
investeren. De term Business Intelligence is een soort parapluterm waar we veel onder
zouden kunnen scharen. Een exacte definitie is dan ook moeilijk, maar zou zoiets
kunnen zijn als: Business Intelligence beoogt iedereen in een organisatie op het juiste
moment van de juiste informatie te voorzien, in het juiste formaat. Deze definitie
is eigenlijk een zinnetje dat bij de introductie van relationele databases in de jaren
zeventig al gebruikt werd. Blijkbaar heeft de relationele database toch niet gebracht
wat er toentertijd van gedacht werd, anders was Business Intelligence nu niet zo groot
geweest. Waarom is dat?
Er is een aantal oorzaken aan te wijzen waarom de relationele database met een rapportageomgeving niet voldoet:
V Bedrijven hebben niet één database, maar meer databases.
V De kwaliteit van de gegevens in databases laat te wensen over.
V De performance van de databases is niet toereikend.
V Gegevens worden overschreven door nieuwe gegevens.
Bedrijven hebben niet één database maar meer databases
Het eerste probleem zit hem in het feit er bijna altijd sprake is van meer dan één
database. De verkoopafdeling werkt met een CRM-pakket (Customer Relationship
Management) waarin onder andere alle orders terechtkomen. De Financiële
Administratie heeft zijn eigen financiële pakket waarin facturen worden ingeboekt,
grootboekposten worden aangemaakt en betalingen worden verwerkt. We zouden
in staat moeten zijn uit beide systemen de omzet te halen. Alle orders uit een periode
tezamen bepalen de omzet van die periode. Net zo goed is de omzet de som van alle
betalingen uit een periode. Toch blijkt in de praktijk keer op keer dat beide systemen
met een ander antwoord komen, met soms grote verschillen tussen beide antwoorden.
Deels zal het probleem hier zitten in definities. Wat is nu eigenlijk omzet? Wat verstaan we daar precies onder? En wanneer reken je iets als omzet: als de klant zijn handtekening zet, als je zelf je goederen of diensten levert, of als het geld op je rekening
wordt bijgeschreven? Er is een grote kans dat verschillende systemen verschillende
definities gebruiken. Dat is meteen een belangrijke les voor iedereen die rapporten
gaat maken: zorg dat definities helder zijn voordat je begint, documenteer deze definities en gebruik consequent dezelfde definities in verschillende rapporten.
Kwaliteit van de gegevens in databases laat te wensen over
Een andere oorzaak van onbetrouwbare antwoorden zit hem in de kwaliteit van de
gegevens. Veelal zijn gegevens handmatig ingevoerd (dat wordt overigens wel steeds
minder) of de gegevens zijn nog ergens handmatig verwerkt, dan wel bewerkt. En
waar mensen werken, worden fouten gemaakt. Een komma is zo verkeerd gezet, maar
kan wel een factor tien schelen in een bedrag, waardoor totalen niet meer kloppen.
2
Hoofdstuk 1 – Inleiding informatiemanagement
Daarnaast zijn gegevens vaak incompleet, zoals postcodes die niet zijn ingevuld. Een
ander veel voorkomend probleem is dat van de dubbele gegevens. Een klant komt in de
database eenmaal voor met de toevoeging B.V. en eenmaal zonder. Dezelfde klant komt
dan vaker in de database voor, wat analyses als omzet per klant onbetrouwbaar maakt.
Er bestaan bedrijven die niets anders doen dan databases van hun klanten opschonen
om bovenstaande problemen zo veel mogelijk op te lossen.
De performance van de databases is niet toereikend
Naast bovengenoemde kwaliteitsproblemen zijn er ook nog performance-issues.
Informatie uit de database krijgen, houdt in: een query schrijven, oftewel een SQL
SELECT-statement schrijven als de database een relationele database is. En SQL lijkt
misschien een beetje op Engels, en dus zou het makkelijk moeten zijn een vraag te
formuleren, de praktijk is toch anders. Al was het maar dat een database uit honderden
tabellen kan bestaan en je als queryschrijver de tabelstructuur moet kennen om te
weten welke tabellen je nodig hebt en hoe die tabellen onderling bij elkaar horen. Vaak
is degene die op businessgerelateerde vragen antwoorden zoekt (de gebruiker van de
rapporten) niet degene die SQL beheerst en/of niet de persoon die de rechten heeft om
die vragen zelf rechtstreeks aan de database te stellen. Maar als de gebruiker zijn vraag
eerst moet uitleggen aan iemand van ICT en die ICT-er, gezien zijn/haar volle agenda,
dan een week later pas de query gaat schrijven, duurt het lang voordat de gebruiker
antwoord krijgt. Veel te lang.
Los van dit kennisprobleem (heeft de gebruiker wel de technische kennis om rapporten te maken?) is er ook een performanceprobleem van meer technische aard. De
meeste operationele systemen hebben wat we noemen ‘uitgenormaliseerde data­
bases’. Dat houdt in dat niet alle gegevens in één en dezelfde tabel zitten, maar dat
de ge­gevens verdeeld zijn over meer tabellen, met als uitgangspunt om redundantie
(het dubbel opslaan van gegevens) te voorkomen. Dat is goed voor zowel de snelheid
waarmee we in de database kunnen schrijven (nieuwe informatie invoeren, maar ook
bestaande gegevens aanpassen) alsook voor de kwaliteit van de gegevens. Maar door
normaliseren wordt het complexer de gegevens uit de database te halen. De leessnelheid wordt slechter. We zullen namelijk in bijna alle gevallen gegevens uit meer tabellen moeten halen (oftewel joins schrijven). En los van het feit dat het schrijven van de
query daar lastiger van wordt, moet de database die complexe query oplossen en daar
heeft de database uiteraard tijd voor nodig.
Met een beetje pech krijgen we er nog locking- en blockingproblemen bij waardoor de
performance nog slechter wordt. Blocking treedt op als de ene gebruiker gegevens aan
het wijzigen is en de andere gebruiker op hetzelfde moment die gegevens wil lezen.
Het lezen zal moeten wachten tot het schrijven klaar is. Wachten vertaalt zich in deze
context natuurlijk tot slechte performance.
Gegevens worden overschreven door nieuwe gegevens
Een ander probleem waar sommige databases mee te maken hebben, is het probleem
dat gegevens vaak overschreven worden door nieuwe gegevens zonder de oude ge­
3
Aan de slag met Reporting Services 2012
gevens te bewaren. Stel bijvoorbeeld dat een verkoper die verantwoordelijk is voor de
regio Noord gaat verhuizen naar Maastricht. Om zijn reistijd te beperken verandert hij
ook van regio, hij wordt verantwoordelijk voor de regio Zuid. In veel systemen wordt
nu Noord overschreven door Zuid. Voor de dagelijkse gang van zaken geen probleem.
Maar als we nu proberen te analyseren hoe veel omzet is gerealiseerd in de regio Zuid
en we die analyse doen via de verantwoordelijke verkoper, blijkt de omzet veel hoger
uit te komen dan wat echt gerealiseerd is. De omzet van voor de verhuizing is meeverhuisd naar de regio Zuid.
Kortom, voor een eenduidig, betrouwbaar en snel rapportagesysteem hebben we
waarschijnlijk meer nodig dan een mooie rapportagetool en een database. Niet alle
bedrijven hebben bovenstaande problemen. Het hangt af van de grootte van het bedrijf
(hoeveelheid data, hoeveelheid databases, hoeveelheid gebruikers), de mate van integratie tussen de verschillende systemen en de performance-eisen die we zelf stellen.
Is er sprake van één of meer van de bovenstaande problemen, dan kan wellicht een
datawarehouse een oplossing bieden.
1.2
Het datawarehouse
Voordat bedrijven die te kampen hebben met boven beschreven problemen meteen
een volledig datawarehouse gaan inrichten, is er misschien nog een tussenoplossing
mogelijk. Regelmatig wordt er een zogenaamde rapportagedatabase gemaakt. In de
meeste gevallen is dat niet meer dan een kopie van de operationele database waarop de
rapporten dan gebaseerd worden. Een belangrijke reden om een rapportagedatabase te
maken is offloading van de rapportageworkload naar een ander systeem. Met andere
woorden: één systeem wordt gebruikt voor de dagelijkse processen, een ander systeem
wordt gebruikt om uit te lezen. Het schrijven en tegelijkertijd lezen, levert nu geen concurrencyproblemen (het tegelijkertijd werken) meer op, wat zowel voor het operatio­
nele systeem als voor het rapportagesysteem performanceproblemen kan oplossen.
De implementatie kan heel eenvoudig zijn. Zet bijvoorbeeld elke nacht de back-up van
de operationele database, die hoogstwaarschijnlijk toch gemaakt wordt, terug op een
andere server. Nadeel is natuurlijk dat de rapportages nu niet meer real-time zijn. De
informatie die in de rapporten getoond wordt, is nu maximaal een dag oud. Uiteraard
kunnen hier met iets genuanceerdere technieken betere resultaten behaald worden.
Een rapportagedatabase lost misschien een deel van de problemen op, maar zeker niet
alle. De volgende stap zou kunnen zijn een datawarehouse in te gaan richten. Van een
datawarehouse wordt weleens gezegd dat het de ‘single version of the truth’ is, dan wel
moet zijn. Oftewel, niet langer verschillende databases met andere antwoorden, maar
één centrale database (het datawarehouse) voor alle vragen en analyses. En met maar
één systeem, is er maar één antwoord. Niet langer andere data en verschillende definities omdat er toevallig verschillende databases zijn. Het datawarehouse wordt gevoed
vanuit de verschillende bronnen. Daarbij wordt gekozen voor centrale definities van
zaken zoals omzet en cost of sales en worden gegevens die kwalitatief niet voldoen
4
Hoofdstuk 1 – Inleiding informatiemanagement
aan de eisen aangevuld en opgeschoond (voor zover mogelijk) tot ze wel voldoen. Met
andere woorden: het datawarehouse is een database die de waarheid bevat.
Een datawarehouse is uiteindelijk gewoon een (relationele) database. Dat wil zeggen
dat we tabellen maken en de gegevens opnemen in die tabellen. Een voordeel van een
datawarehouse ten opzichte van een rapportagedatabase (zoals eerder besproken), is
dat we een nieuwe tabelstructuur kunnen bedenken voor het datawarehouse. En die
structuur kunnen we optimaliseren voor het doel waarvoor het datawarehouse dient:
rapporten maken en analyses doen ten behoeve van de besluitvorming in een bedrijf.
Veel lezen dus in de database en niet of nauwelijks schrijven. Een model dat daar uitermate geschikt voor is, is het stermodel.
1.3
Het stermodel
Over wat de beste structuur voor een datawarehouse is, bestaat nog veel discussie.
De eerste die met een modelleringstechniek voor datawarehouses kwam was Ralph
Kimball. Hij is de bedenker van dimensioneel modelleren en daarmee van het ster­
model. Bill Inmon was een andere pionier op het gebied van datawarehousing en
kwam met een andere architectuur. Relatief nieuw is de door Dan Linstedt bedachte
Data Vault, een derde manier om een datawarehouse op te zetten. Het gaat te ver om
hier alle drie de architecturen te bespreken. Een grote overeenkomst is echter dat alle
drie zeggen dat het stermodel een goede tabelstructuur is om op te rapporten. Vandaar
dat we het stermodel hier wel kort zullen beschrijven.
Figuur 1.1 Voorbeeld van een stermodel met de feitentabel factResellerSales in het midden
5
Aan de slag met Reporting Services 2012
In figuur 1.1 ziet u een voorbeeld van een stermodel. In latere hoofdstukken gaat u
op basis van deze tabellen rapporten maken. De naam stermodel komt voort uit de
structuur. Er is één centrale tabel, de feitentabel, met eromheen een aantal tabellen, de
zogenaamde dimensietabellen.
De feitentabel
Bij een sterschema (stermodel) gaan we uit van een proces in de organisatie waar we
rapportages en analyses voor moeten maken. De eerste stap is het bepalen van de
feiten rond dit proces. Hoe is het proces te meten? Wat bepaalt dat een proces succesvol
verloopt of niet? Voor een verkoopproces liggen zaken als omzet, marge, kosten, verkochte aantallen, et cetera, voor de hand. Over het algemeen hebben we het daarmee
over numerieke grootheden. Aggregeerbare grootheden ook, want van dagomzetten
kunnen we ook weekomzetten maken.
De tweede belangrijke stap is het bepalen van de grain, oftewel het detailniveau waarop we de gegevens willen bijhouden. Willen we omzet per dag of per week bijhouden?
Of is tijd hier eigenlijk niet direct van belang, maar is het beter omzet per verkochte
order bij te houden? Een verkeerd detailniveau kiezen is desastreus. Van dagomzetten kunnen makkelijk weekomzetten berekend worden (gewoon de zeven dagen van
dezelfde week bij elkaar optellen), maar terug van weekomzetten weer dagomzetten
maken, is niet meer mogelijk. Simpel de weekomzet door zeven delen levert immers
niet het juiste resultaat. De keerzijde is dat het opslaan van meer details direct leidt
tot meer data en dus een grotere database met de bijbehorende performance-issues tot
gevolg. Omdat het hier gaat om de meetbare feiten van een proces, wordt de tabel waar
het hier over gaat de feitentabel genoemd.
De dimensietabellen
Vervolgens bepalen we de zogenaamde dimensies, de grootheden die binnen het
proces dat we beschrijven een rol spelen. De keuze voor het detailniveau geeft ons al
veel informatie. Stel dat we als detailniveau gekozen hebben voor: de omzet per dag,
per product, per winkel. Dit levert meteen drie dimensies op: een datumdimensie die
bijna altijd aanwezig is, een productdimensie en een winkeldimensie. Blijkbaar gaat
het hier om het verkopen van producten in winkels van een winkelketen. Naast de
dimensies die we nu gevonden hebben, bestaan er misschien nog wel andere dimensies. We zouden kunnen denken aan een verkoperdimensie, reclameactiedimensie, et
cetera. Het kennen en doorgronden van het proces dat we modelleren is cruciaal voor
het bedenken van de juiste dimensies en dus voor het ontwikkelen van de het juiste
stermodel.
De dimensietabellen zijn zogenaamde ‘platgeslagen’ tabellen. Daarmee wordt bedoeld
dat de tabellen niet uitgenormaliseerd zijn zoals in de meeste operationele databases.
Ze staan bol van de redundantie (dubbele gegevens). In een OLTP-systeem is dat, zoals
eerder gezegd, slecht voor zowel de kwaliteit van de gegevens als voor de performance
van de database. Daarbij wordt dan wel de schrijfperformance van de database bedoeld. Voor het lezen, en daar gaat het natuurlijk om in een datawarehouse, heeft het
juist veel voordelen om niet te normaliseren. De gegevens worden makkelijker en
6
Hoofdstuk 1 – Inleiding informatiemanagement
sneller benaderbaar. Stel bijvoorbeeld dat het salesproces in het bovengenoemde voorbeeld om groentewinkels gaat. Alle aardappels worden ingekocht door een inkoper
genaamd Jan. Alle aardappels hebben een prijs per kilo (geen stuksprijs). De productdimensie zou er nu als volgt uit kunnen zien.
ProductNummer
ProductNaam
ProductType
Inkoper
PrijsType
Prijs
1
Bintje
Aardappel
Jan
Per kilo
2,00
2
Eigenheimer
Aardappel
Jan
Per kilo
2,50
De kolommen Inkoper en PrijsType zijn hier redundant. De waarde van de kolommen
volgt immers uit het feit dat het ProductType Aardappel is. In een genormaliseerd
systeem zouden we hier twee tabellen van maken.
De dimensies in een stermodel geven betekenis aan de feiten uit de feitentabel. We
vullen de dimensietabel met zo veel mogelijk beschrijvende informatie, veelal character strings. Dus waar de feitentabel vooral uit numerieke gegevens bestaat, bestaan
dimensietabellen veelal uit kolommen met tekst. Via deze beschrijvende kolommen
kunnen we analyseren en filteren.
Met de feitentabel en de bijbehorende dimensietabellen is het stermodel af. Uiteraard
zijn er veel uitzonderingen en speciale gevallen. Over dimensioneel modelleren zijn
hele boeken volgeschreven, dus bovenstaande korte beschrijving is verre van accuraat
en volledig.
Als we het ERD (entiteitenrelatiediagram) tekenen, oftewel het plaatje van de tabellen
en hun onderlinge verbanden, zien we waarom het een stermodel wordt genoemd.
Centraal staat de feitentabel met daaromheen de dimensietabellen, zodat het geheel er
enigszins uitziet als een ster. Zo’n ster bestaat over het algemeen uit slechts een paar
tabellen. Eén feitentabel met negen dimensies, dus tien tabellen tezamen, is al redelijk
veel. Geen tientallen, honderden of zelfs meer, zoals bij uitgenormaliseerde databases
wel normaal is. Een gevolg daarvan is dat het schrijven van queries makkelijker wordt.
Bovendien hebben moderne databasesystemen, zoals SQL Server, speciale optimalisaties die queries op sterschema’s extreem efficiënt kunnen uitvoeren. Een sterschema
is dus goed voor het gebruikersgemak (degene die de queries schrijft en dus degene die
rapporten maakt) en voor de performance.
Met een datawarehouse kunnen we dus de gegevens van meer databases, eventueel
zelfs aangevuld met gegevens uit externe bronnen, samenbrengen in één grote
database. Bovendien kunnen we met het overhalen van de gegevens naar het datawarehouse, het ETL-proces (Extract, Transform, Load), de kwaliteit van de gegevens en daarmee van de informatie, aanpassen. En door de mogelijkheid een andere server en een
ander databasedesign te kiezen, kunnen we de performance sterk verbeteren. Maar
zoals altijd in de databasewereld, is er een prijs voor al die voordelen. De gegevens
zijn even up-to-date als de laatste keer dat het datawarehouse is gevuld. De rapporten
7
Aan de slag met Reporting Services 2012
geven dus geen real-time informatie, maar een beetje verouderde informatie. Vaak
zien we dat datawarehouses elke nacht opnieuw gevuld worden, maar andere schema’s
zijn natuurlijk ook mogelijk. Wat wijsheid is qua vulschema’s, hangt af van de eisen
die de business stelt aan de informatie die uit het datawarehouse moet komen en van
de grootte van de hoeveelheid data. Maar hoe erg is het eigenlijk als rapporten geen
real-time informatie bevatten?
1.4
Soorten beslissingen
Eerder hebben we als definitie voor Business Intelligence gebruikt: Iedereen in een
organisatie op het juiste moment van de juiste informatie voorzien, in het juiste
formaat. Daaraan moeten we eigenlijk toevoegen: met als doel beslissingen te kunnen
nemen op basis van betrouwbare informatie (in plaats van op basis van een onderbuikgevoel of slechts ‘ervaring’ van de betrokken persoon). De mensen moeten goed
geïnformeerd zijn, zodat ze op basis van die informatie de goede beslissingen kunnen
nemen. Maar wie neemt welke beslissingen?
Microsoft kwam bij de introductie van SQL Server 2005 met de slogan: ‘BI for the masses.’ Met andere woorden, iedereen, van hoog tot laag, neemt weleens beslissingen. En
voor iedereen geldt: die beslissingen zouden gebaseerd moeten zijn op informatie.
Uiteraard is er wel verschil tussen de verschillende beslissingen en de impact die een
beslissing heeft op de totale business. In de literatuur worden drie soorten beslissingen onderscheiden: strategische beslissingen, tactische beslissingen en operationele
beslissingen.
Strategische beslissingen
Strategische beslissingen zijn beslissingen ten aanzien van de strategie van een bedrijf. Waar willen we heen? Hoe moet het bedrijf er over vijf jaar uitzien? Hoe reageren
we het beste op de crisis, zodat we de crisis goed doorstaan en er het liefst sterker uitkomen dan we erin gingen? Dit soort besluiten kenmerkt zich door een lage frequentie, maar een hoge impact op de business en daarmee op de mensen. Een ICT-opleider
zou zich bijvoorbeeld in crisistijd, als er weinig cursussen worden gevolgd, kunnen
omvormen tot een consultancybedrijf. De docenten moeten dan consultants worden
die gedetacheerd worden, verkopers moeten geen cursussen meer verkopen maar
mensen bij klanten plaatsen en de planners raken misschien hun baan wel helemaal
kwijt. Grote impact dus op iedereen. Maar als de kogel eenmaal door de kerk is, moet je
deze koers blijven varen. Je kunt niet na één maand alweer het roer omgooien.
Om een beslissing, zoals hierboven beschreven, gefundeerd te kunnen maken, heb je
veel informatie nodig. Het management wil de omzet, marge en winstcijfers van de
afgelopen jaren hebben. Hoe zijn we gevaren tijdens de vorige crisis? Het liefst moet
deze informatie aangevuld worden met externe informatie. Hoe deden de concurrenten het toen? Hoe reageerde de markt toen en verwachten we nu een zelfde reactie? Om
dit soort vragen te kunnen beantwoorden zijn veel gegevens nodig, namelijk omzet-
8
Hoofdstuk 1 – Inleiding informatiemanagement
en margegegevens over meerdere jaren. Daarbij zijn we niet meer geïnteresseerd in
details, maar in geaggregeerde data. Individuele cursisten en cursussen zijn niet meer
interessant. De totale omzet is interessant. Individuele klanten zijn niet meer interessant, maar wel de vraag welke branches het ondanks de crisis goed bleven doen. Veel
data dus, samengepakt tot een beperkte hoeveelheid informatie. Van real-time eisen
aan de informatie is hier geen, of zo goed als geen sprake.
Tactische beslissingen
De tweede soort beslissingen is die van de tactische beslissingen. Tactische beslissingen horen voornamelijk thuis bij het middenmanagement. Ze gaan over de uitvoer.
Hoe brengen we de gekozen strategie in de praktijk ten uitvoer? Over het algemeen
wordt dit per afdeling bekeken. Er worden doelstellingen bepaald en die doelstellingen
moeten gecontroleerd worden. Zitten we nog op schema? Gaan we de doelstellingen
halen? Deze vraag kan een manager van een afdeling zich stellen, maar een teamleider kan zich die vraag ook stellen voor zijn team en een individuele werknemer voor
zichzelf. Deze vragen en de besluiten waartoe de antwoorden leiden, kenmerken zich
door een hogere frequentie dan strategische besluiten. De impact is beperkter en de
hoeveelheid gegevens die we nodig hebben om zinvolle informatie te leveren om de
besluiten weer goed onderbouwd te nemen, is kleiner. Het gaat eerder over maanden
dan jaren en eerder over afdelingen of teams dan over het hele bedrijf. Nog steeds is er
niet echt sprake van een harde eis voor real-time informatie, hoewel daar uitzonderingen op bestaan. Bovendien kunnen de betrokken mensen daar anders over denken. Ik
heb ooit een manager horen eisen dat zijn rapport ten aanzien van het ziekteverzuim
van vorig jaar real-time moest zijn!
Operationele beslissingen
De derde soort beslissingen is die van de operationele beslissingen. Dit zijn de dagelijkse besluiten die bijna iedereen neemt tijdens het uitvoeren van zijn of haar dagelijkse taken. Denk bijvoorbeeld aan een inkoper die op basis van de huidige voorraad
besluit wel of niet extra in te kopen. De frequentie van dit soort beslissingen is heel
hoog, we hebben er niet al te veel informatie voor nodig en de impact van een (verkeerde) beslissing zal niet al te groot zijn. Uiteraard willen we alle processen binnen het
bedrijf zo veel mogelijk optimaliseren en is het dus noodzaak ook deze beslissingen op
basis van accurate informatie te nemen, in plaats van op gevoel of ervaring af te gaan.
Bij operationele beslissingen komen real-time eisen (terecht en onterecht) het meest
voor. Moet een supermarkt nog brood bijbakken als de voorraad bijna op is? Elke
klant die voor een leeg schap staat, is een ontevreden klant die misschien wel naar de
concurrent overstapt. Maar elk brood dat na sluitingstijd nog niet verkocht is, moet
worden weggegooid en dat is kapitaalvernietiging. Voor zo’n beslissing heb je niets
aan de voorraad en het aantal verkopen van gisteren. Actuele informatie is nu opeens
van groot belang.
9
Aan de slag met Reporting Services 2012
1.5
Soorten rapporten
In de eerder gekozen definitie van Business Intelligence staat ook dat mensen de informatie in het juiste formaat moeten krijgen. Deels sluit dat aan bij het bovenstaande
verhaal over soorten beslissingen. Deels gaat het ook over de mensen die de informatie
moeten krijgen en hoe die mensen werken. Operationele rapporten zijn heel vaak
lijstjes. Bijvoorbeeld een lijst van klanten van wie het abonnement bijna afloopt, of een
lijst van mensen die trial software van de website hebben gedownload. Of een lijst van
producten waarvan de voorraad onder een kritieke grens is gezakt, en ga zo maar door.
Bij tactische beslissingen horen vaker rapporten die in één oogopslag de stand van
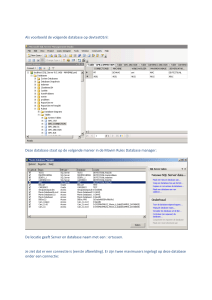
zaken laten zien. Dashboards worden dan interessant. Dashboards laten vaak in een
grafische weergave snel op hoofdlijnen zien hoe iets ervoor staat. Daar horen over het
algemeen ook KPI’s bij. In figuur 1.2 ziet u een voorbeeld van een dashboard.
Figuur 1.2 Dashboard uit SQL Server Management Studio
Een KPI, kritischeprestatie-indicator (key performance indicator), laat zien hoe een
actuele stand van zaken zich verhoudt tot een doelstelling of beoogde stand van zaken.
Meestal gebeurt dat via een icoontje, een stoplicht, een smiley, een uitslaande meter,
of vergelijkbare grafische indicatoren. Is bijvoorbeeld het ziekteverzuim groter dan de
doelstelling, dan staat het stoplicht op het dashboard van de HRM-manager op rood.
Extra bij een dashboard hoort vaak dat de gebruiker kan klikken om meer detailinformatie te krijgen, bijvoorbeeld het verzuim per afdeling, per dag.
Rapporteren versus analyseren
Zowel op tactisch als strategisch niveau is het analyseren van processen met behulp
van gegevens ook vaak van belang. We moeten ons afvragen of rapporten geschikte
tools zijn om te analyseren. Analyseren is iets dynamisch en rapporten zijn vrij sta-
10
Hoofdstuk 1 – Inleiding informatiemanagement
tisch, zelfs als ze veel interactieve elementen zoals drill-down bevatten. Drill-down
betekent zoveel als doorklikken naar meer gedetailleerde informatie.
Rapporten zijn vooraf gemaakt, met een vooraf gedefinieerd doel. Analyseren kan je
brengen op nieuwe terreinen, bij nog niet eerder gestelde vragen en dus bij informatie
die nog niet is verwerkt in standaard rapporten. Maar met grafieken en draaitabellen
kunnen we al een aardige stap maken. We zouden in een brainstormsessie willekeurige vragen moeten kunnen stellen (‘out of the box’ denken) en meteen de antwoorden
moeten kunnen zien. Dat is waar analyseren echt begint en waar we voorbij het punt
komen van wat rapporten te bieden hebben.
Wie is de gebruiker?
Een rapportagesysteem dat theoretisch perfect is maar niet gebruikt wordt, is een
slecht systeem. De mensen moeten de rapporten wel gebruiken. Ten eerste moet de
informatie op de rapporten dus kloppen, betrouwbaar zijn. Daarnaast moeten de mensen er prettig mee werken. Helaas is dat een subjectief verhaal.
Neem een wat oudere directeur die nog net heeft leren e-mailen, maar voor alle
overige computergerelateerde zaken afhankelijk is van zijn of haar secretaresse.
Waarschijnlijk is het beste rapport in dit geval een rapport in PDF-formaat dat reeds
door iemand anders is geprint. Maar iemand met veel meer computervaardigheden
en met misschien zelfs een technische achtergrond en inzicht in de beschikbare ge­
gevens, neemt niet zomaar genoegen met een papieren uitdraai. Een rapport in Excel
waar hij zelf zijn eigen filtering, sortering en zelfs bewerkingen aan kan toevoegen, is
beter geschikt.
Sommige bedrijven gebruiken Excel juist niet vanwege alle bewerkingen die mensen
er dan nog mee kunnen doen. Dat komt de eenduidigheid en herleidbaarheid van de
informatie namelijk niet ten goede. Met een beetje pech discussiëren we alsnog over
welk rapport klopt, in plaats van het te kunnen hebben over door iedereen vertrouwde
rapportages en daarmee over de inhoud. Wellicht is een rapport in HTML, dus op het
scherm, met de juiste interactieve mogelijkheden wel een goede tussenoplossing. Het
hangt allemaal af van de gebruiker. Dus is het kennen van de gebruiker en hoe een rapport gebruikt gaat worden een belangrijk aspect bij het ontwikkelen van rapporten.
Analyse vooraf
Samenvattend kunt u concluderen dat het heel belangrijk is om te weten met welk
doel u een rapport gaat ontwikkelen en wie de gebruikers van het rapport zullen zijn.
Welk proces moet ondersteund worden? Wie gaat er welke beslissingen op baseren?
Hoe kunt u de benodigde kennis die een beslissing vergt het beste inzichtelijk maken?
Wat zijn de vaardigheden van de gebruikers?
Op basis van deze vragen moet, samen met de beoogde gebruikers, een rapportopzet
gemaakt worden. U kunt sturen, en via prototypes mogelijkheden aandragen. De gebruiker moet het accepteren, de meerwaarde zien, en het rapport uiteindelijk gebruiken.
11
Aan de slag met Reporting Services 2012
1.6OLAP-kubus
Een belangrijke vraag die bij het maken van een rapport beantwoord moet worden, is:
waar zullen de gegevens vandaan komen? Tegenwoordig wordt veel gebruikgemaakt
van OLAP-kubussen, en dus is er een goede kans dat SQL Server Analysis Services
uw bron wordt. Analysis Services is de Microsoft-tool om kubussen te maken en te
beheren.
De afkorting OLAP staat voor Online Analytical Processing. Hier komen we het woord
analyse weer tegen. En Analysis Services heeft zijn naam ook niet voor niets gekregen.
In de vorige paragraaf is al gezegd dat rapporteren eigenlijk iets vrij statisch is, terwijl
analyseren juist dynamisch moet zijn. Willekeurige vragen kunnen stellen en razendsnel antwoorden krijgen (‘free form questions, answers at the speed of thought’). Met
een relationeel datawarehouse gaat dat zeker niet lukken. Voordat zelfs een ervaren
SQL-programmeur de query heeft geschreven (of bij elkaar geklikt) is er al zo veel tijd
verstreken dat we allang niet meer van razendsnel kunnen spreken. En dan moet de
query nog uitgevoerd worden. Kubussen moeten aan dit probleem tegemoet komen.
Excel on steroïds
Een kubus zouden we kunnen zien als een grote, meerdimensionale draaitabel. Een
gewone draaitabel bestaat uit twee assen en de snijpunten (cellen) van die assen. Op
de ene as staan bijvoorbeeld alle producten die verkocht worden, op de andere as staan
alle maanden van het jaar en in de cellen (elke cel is het snijpunt van een product met
een maand) staat het aantal dat van het betreffende product in die maand is verkocht.
Draaitabellen vormen een belangrijke reden waarom Excel zo populair is geworden.
Een kubus kan je zien als ‘Excel on steroïds’. Het is een draaitabel zoals in Excel, maar
dan niet beperkt tot twee assen, maar met net zo veel assen als u nodig heeft.
Figuur 1.3 Draaitabel in Excel met omzet per productcategorie per jaar
Denk nog eens terug aan het eerder besproken stermodel. Een stermodel bestaat uit
een feitentabel met daarin voornamelijk numerieke zaken, zoals aantallen, omzet,
marge, et cetera, en dimensietabellen met beschrijvende zaken die context (betekenis)
geven aan de feiten. Dit sluit naadloos aan bij een kubus. De assen van de kubus zijn
de dimensies, de cellen vullen we met de feiten. Omdat er meer dan twee dimensietabellen voorkomen in een stermodel, hebben we ook meer dimensies in een kubus.
Kubussen worden dan ook wel ‘multidimensionele databases’ genoemd.
12
Hoofdstuk 1 – Inleiding informatiemanagement
MDX
Een tweede reden waarom Excel zo populair is, naast de draaitabelfunctionaliteit, is
de rekenkracht. Met formules maakt u gemakkelijk berekende velden. Voor kubussen geldt weer hetzelfde. Zoals de taal SQL bij relationele databases hoort, zo hoort de
taal MDX (Multi Dimensional eXpressions) bij kubussen. Met MDX zijn we in staat
om relatief eenvoudig, complexe berekeningen te maken. Soms is een berekening in
MDX gewoon eenvoudiger dan het programmeren van dezelfde berekening in SQL.
Sommige berekeningen zijn in SQL helemaal niet mogelijk, maar wel in MDX. MDX
heeft onder andere een rijke verzameling aan statistische en financiële functies die we
kunnen gebruiken. En het resultaat van deze berekeningen kunnen we gebruiken om
cellen te vullen en dus om de gegevens in de kubus te verrijken.
Slice and dice
Een uitdrukking die hoort bij kubussen, en die goed aansluit bij wat analyseren is,
is ‘to slice and dice’. Dat vertaalt zich misschien het beste naar willekeurig door je
gegevens browsen. ‘To slice’ betekent een ‘plakje’ uit je kubus snijden, oftewel een
filter definiëren. Als we bijvoorbeeld geïnteresseerd zijn in omzetgegevens over 2012,
dan zetten we een filter op jaartal. Alles wat vanaf nu uit de kubus komt, heeft alleen
nog maar betrekking op 2012. Als we dus nu de lijst van producten met bijbehorende
omzet opvragen, krijgen we alleen producten te zien die in 2012 verkocht zijn, met de
bijbehorende omzet.
‘To dice’ betekent dat je willekeurige cellen in de kubus kunt benaderen door op de
dimensies de juiste elementen (dimension members) te selecteren. Al met al kunnen
we dus als het ware real-time door de gegevens in de kubus wandelen. Dat wil zeggen,
als we de juiste tools hebben. Excel is zo’n tool. Het is een geweldige analyseomgeving
die goed aansluit op kubussen (met name SQL Server Analysis Services). Reporting
Services is goed in staat gegevens uit een kubus te halen en daar een rapport van te
maken. Reporting Services behandelt de gegevens echter precies zoals het gegevens
uit een relationele database behandelt. Het vuurt de query af op de database, in het
geval van een kubus dus een MDX-query, en toont de gegevens in het formaat zoals de
ontwikkelaar van het rapport heeft bedacht. Het interactieve element van willekeurig
door je gegevens wandelen, is daarmee grotendeels weg.
1.6.1
Voordelen van kubussen
Zoals hierboven beschreven sluiten kubussen goed aan op het begrip analyseren. Een
kubus is als het ware een grote, krachtige spreadsheet met meer dimensies en een
krachtige expressietaal. Maar er zijn meer voordelen. Het automatisch laten genereren
van queries gaat beter dan bij relationele databases en de performance is (vaak) beter.
Genereren van queries
Onafhankelijk van het soort database moet er een query naar de database gestuurd
worden om gegevens terug te krijgen. Voor een kubus is dat een MDX-query, voor
een relationele databases is dat een SQL-query. Veel tools kunnen queries genereren.
Daarnaast zijn er grafische tools die ons helpen queries in elkaar te slepen, in plaats
13
Aan de slag met Reporting Services 2012
van ze zelf te moeten schrijven. Voor beide geldt over het algemeen dat deze tools beter
zijn met kubussen dan met relationele databases.
Tools die queries maken, of die ons helpen queries te maken, zijn afhankelijk van het
ontwerp van de database. Als in een relationele database geen relaties tussen tabellen
zijn gedefinieerd (foreign keys), kunnen ze vaak niet de juiste query maken. Als dat
wel lukt, is het nog maar de vraag of het ook een query is die goede performance zal
laten zien.
Bij het ontwerpen van kubussen wordt rekening gehouden met de gebruiker. Relaties
tussen feiten en dimensies worden vastgelegd. Daardoor zijn tools veel beter in staat
goede MDX-queries te genereren dan dat ze SQL-queries kunnen genereren. Dat houdt
op zijn beurt in dat iemand met weinig kennis van de querytaal, maar met goede tools,
met kubussen verder komt dan met relationele databases.
Performance
Kubussen hebben naast dat ze dynamisch analyseren faciliteren nog een ander voordeel. Bij veel analyses en rapportages is er sprake van een hoog aggregatieniveau. Om
de dagomzet van een supermarkt te berekenen, moeten duizenden kassabonregels
worden opgeteld. Om de landelijke dagomzet van de hele supermarktketen te berekenen of om de weekomzet te berekenen, wordt dat nog vele malen meer. Door die grote
hoeveelheid data is dit soort operaties ogenblikkelijk duur, waarbij ik met duur denk
aan performance. Rapporten die dit soort feiten tonen, zullen nooit een heel goede
performance laten zien.
Om de performance van rapporten die hooggeaggregeerde data tonen te verbeteren,
wordt binnen datawarehouses vaak gebruikgemaakt van aggregatietabellen. Dat
houdt in dat de dagomzet of weekomzet (of misschien wel beide) van de supermarkt
’s nachts berekend wordt. Van het resultaat van de berekening wordt een aparte tabel
gemaakt. Het rapport kunnen we nu baseren op deze aggregatietabel. Daardoor is de
hoeveelheid data die het rapport opvraagt veel kleiner en dat levert veel performancewinst op. Bovendien hoeft er niet meer gerekend te worden aan de data zoals die uit de
database komt, wat nog eens veel performancewinst oplevert. Dubbele winst dus.
Het nadeel van deze truc (de aggregatietabel) zit hem voornamelijk in de afhankelijkheid van het rapport met de aggregatietabel. De persoon die de query schrijft, moet op
de hoogte zijn van het bestaan van de tabel en deze gebruiken, in plaats van de nietgeaggregeerde feitentabel te gebruiken. Een rapport met een net iets andere insteek
kan misschien wel, maar misschien ook niet profiteren van dezelfde aggregatietabel.
Maandomzetten zijn immers niet te berekenen uit weekomzetten, omdat een nieuwe
maand halverwege een week kan beginnen. Dus het rapport dat maandomzetten toont
kan geen gebruikmaken van de aggregatietabel met weekomzetten. Bovendien maakt
een rapport niet automatisch gebruik van de juiste aggregatietabel. De query die de
basis vormt van het rapport is hardcoded. Als we een rapport sneller willen maken
door een aggregatietabel die aansluit bij het rapport alvast vooraf te maken, moet het
rapport ook aangepast worden.
14
Hoofdstuk 1 – Inleiding informatiemanagement
Bovenstaand probleem wordt, als een kubus goed ontworpen is, door kubussen opgelost. De oplossing is eigenlijk hetzelfde als wat hierboven beschreven is, namelijk
vooraf al aggregaties berekenen en deze in de kubus opnemen. Tijdens het uitvragen
van de kubus zijn daardoor minder berekeningen nodig waardoor we een betere
performance mogen verwachten. Het grote verschil met aggregatietabellen in een
relationele database is dat de ‘slimheid’ om deze aggregaties ook daadwerkelijk te gebruiken is ingebakken in de queryengine. Als we met MDX een geaggregeerde waarde
opvragen uit de kubus, kijkt de kubus automatisch of er een aggregatie aanwezig is.
De waarde wordt alleen berekend als er geen aggregatie aanwezig is. Als het goed is,
gebruikt de kubus zelfs aggregaties om aggregaties op een hoger niveau te berekenen.
Stel: er zijn aggregaties gemaakt voor maandomzetten en er wordt in een query om
kwartaalomzetten gevraagd. In dat geval zal de kubus herkennen dat een kwartaal bestaat uit drie maanden, de drie betreffende maandomzetten ophalen, optellen, en het
resultaat teruggeven. Het mooie hiervan is dat de query precies hetzelfde blijft. Als we
dus constateren dat een rapport traag is omdat de onderliggende query geen gebruikmaakt van aggregaties, kunnen we de kubus aanpassen, zodat de juiste aggregaties in
de kubus aangemaakt worden en het rapport zal deze automatisch gaan gebruiken.
Samenvattend zijn er twee redenen waarom we rapporten zouden willen baseren op
een kubus. Allereerst is dat de extra functionaliteit die wellicht al in de kubus zit. Met
MDX kan de kubus verrijkt zijn met complexe berekeningen. Vanuit het perspectief
van het rapport zijn die berekeningen gewoon cellen (velden) die we kunnen gebruiken zonder zelf complexe (en daarmee waarschijnlijk trage) queries te schrijven.
Daarnaast biedt een kubus vaak voor vergelijkbare queries een betere performance,
zeker als de queries niet om detailgegevens vragen maar geaggregeerde data opvragen.
1.6.2
Tabular Model
Met SQL Server 2012 heeft Microsoft naast de boven beschreven kubussen ook de
mogelijkheid gemaakt van Tabular Models. Tabular Models bieden ook goede performance, maar halen dat grotendeels uit het feit dat het in-memory databases zijn.
Tabular Models staan een beetje op dezelfde plaats in een BI-architectuur, tussen het
datawarehouse en de rapportagetools in. Ze moeten het makkelijker maken de data in
het datawarehouse te ontsluiten. U leert meer over Tabular Models in Hoofdstuk 6.
1.7
Ontstaan SQL Server Reporting Services
In 2004 kwam Microsoft SQL Server Reporting Services op de markt. In 2012 kwam
Microsoft SQL Server 2012 op de markt. Nieuw in deze versie is Power View, een eenvoudig te gebruiken rapportagetool. Reporting Services heeft in eerdere versies als
kritiek gekregen dat het vooral een tool voor techneuten was, ondanks het feit dat er
verschillende tools meegeleverd werden voor verschillende doelgroepen.
15
Aan de slag met Reporting Services 2012
Visual Studio
Reporting Services was flexibel van opzet, maar de rapporten moesten gemaakt worden in Visual Studio, dezelfde ontwikkelomgeving waarin ook websites en bijvoorbeeld Visual Basic-applicaties worden gemaakt. Dat was geen probleem voor ontwikkelaars, maar voor sommige gebruikers bleek dat een te moeilijke omgeving. En in de
praktijk worden rapporten vaak gemaakt door de eindgebruikers van die rapporten en
dus niet door ontwikkelaars.
Report Builder
Als alternatief voor Visual Studio was er de Report Builder. Dit was een eenvoudige
drag-and-drop tool om rapporten mee te maken. Een eis voor het gebruik van de
Report Builder was dat er een zogenaamd Report Model bestond. Een Report Model
is een semantische laag. Semantisch komt van het woord ‘semantiek’, dat betekenis
betekent. Het model heeft als belangrijkste doel een abstractielaag te vormen tussen
de database en de rapportbouwer. Het idee is dat de rapportbouwer geen technische
kennis nodig heeft van de onderliggende database en niet zelf queries hoeft te schrijven. Het model ‘vertaalt’ de technische aspecten naar businesstermen en genereert de
benodigde queries. In theorie allemaal erg mooi, maar de functionaliteit van de rapporten bleef ver, te ver, achter bij wat met Visual Studio gemaakt kon worden.
Report Builder 2.0 / 3.0
Als antwoord op de kritiek dat de functionaliteit tekortschoot, kwam Microsoft met
Report Builder 2.0 en later met Report Builder 3.0. Nog steeds was het mogelijk rapporten te baseren op Report Models, maar het was geen vereiste meer. Daarnaast nam het
aantal mogelijkheden van de rapporten sterk toe. Helaas is het in de praktijk meestal
zo dat als een product meer mogelijkheden krijgt, de ontwikkelomgeving ook weer ingewikkelder wordt. En dus schoot Microsoft met de Report Builder 3.0 zijn doel voorbij: voor de doelgroep waarvoor deze tool was ontwikkeld, was hij ondertussen toch
weer te complex geworden. En de mensen waarvoor dat niet geldt, kunnen net zo goed
met Visual Studio werken om op die manier de volledige functionaliteit te hebben.
Power View
Power View is nu het antwoord van Microsoft. Power View beoogt net als de eerste
Report Builder een eenvoudige tool te zijn waarmee iedereen die een beetje met een
computer overweg kan, rapporten kan bouwen. Veel van de ondertussen vertrouwde
functionaliteit van Reporting Services vinden we er niet in terug. En van veel van die
zaken is het nog maar de vraag of we die ooit gaan krijgen. Microsoft wil niet weer de
fout maken van Report Builder 3.0. Bij Power View voelt het echter niet als beperking.
Het biedt mooie functionaliteit en heeft een ander doel dan rapporten gemaakt met
Visual Studio.
Er is een belangrijke overeenkomst met de eerste Report Builder: rapporten die u
maakt met Power View zijn gebaseerd op een model. Voor Power View is dat Analysis
Services Tabular Model, oftewel het Business Intelligence Semantic Model. Dit borduurt voort op de introductie van PowerPivot in Excel en wordt gebouwd in SQL Server
Analysis Services 2012. Meer hierover leest u in Hoofdstuk 6 en 7.
16
Hoofdstuk 1 – Inleiding informatiemanagement
1.8
Tot slot
SQL Server Reporting Services is een tool om gegevens uit databases te tonen aan
gebruikers. Gebruikers kunnen hier beslissingen op baseren, ze kunnen werken met
informatie. Reporting Services kan gebruikt worden om operationele rapporten op
productiedatabases te maken, maar ook om strategische rapportages te maken die op
grote datawarehouses gebaseerd zijn.
Reporting Services komt met een paar tools. Uiteraard zijn er de tools om de rapporten
mee te maken, met verschillende tools voor mensen met verschillende achtergronden.
Ook zijn er tools om een rapportageomgeving mee te beheren.
De rest van dit boek richt zich op wat Reporting Services te bieden heeft en hoe u
Reporting Services kunt gebruiken. In het volgende hoofdstuk leert u eerst hoe
Reporting Services te installeren. Hoofdstuk 3 en 4 gaan over het maken van rapporten in SQL Server Data Tools, oftewel Visual Studio. Hoofdstuk 5 richt zich op het
beheer van de rapporten die u in Hoofdstuk 3 en 4 heeft gemaakt. In Hoofdstuk 6 gaat
u een Business Intelligence Semantic Model maken om daar in het laatste hoofdstuk,
Hoofdstuk 7, met Power View rapporten op te baseren.
17
Index
A
Action 100, 109
Advanced Mode 63, 99
Afdelings-BI 147
aggregate functies 74
aggregatietabel 14
Allow Multiple Values 90
B
Background color 63
bar chart 106
Bookmark 100
Browser 141
Bubble Chart 188
Business Intelligence 2, 8
C
Cache Refresh Options 130
cache warming 137, 139
caching 94, 127
Calculated Field 77
Card 186
CDATE 86
Chart Data Region 57, 106
color 63
Column Groups 72
CONCATENATE 156
conditionele opmaak 69
connectiestring 45
Corporate BI 145
D
dashboard 10
Data Alerts 143
Data Bar 110, 111
Data-driven Subscriptions
135
Data Region 57
Dataset 47
Shared Dataset 47
DataSetName 59
Data Source 45
Shared Data Sources 45
datawarehouse 4
DATEADD 166
datumtabel 165
DAX 155
Default Field Set 167
Default Image 168
default instance 23
Default Label 168
deployen 119
diagramweergave 158
dimensies 6
DirectQuery 171
Document Map 96
double-hop 126
drill-down 97
drill-through 97, 101, 108
Duplicate View 185
E
E-mail Settings 32
Embedded Connection 50
Encryption Keys 32
ExecutionTime 67
exporteren naar PowerPoint
182
Expression Builder 66
F
feitentabel 6
Fields-collectie 76
filteren 84
filters 181
footers 64
friendly name 149
G
Gauges 110, 115
Globals 67
Globals-collectie 76
Groepen 72
group footer 73
group header 73
H
headers 64
HideDuplicates 72
Hide from client tools 164
hiërarchie 158
I
IF 166
IIF 69
Image 64
Impersonate 126
Indicator 110, 113
interactive page size 115
intermediate report 128
Internal 89
K
Keep Unique Rows 167
Kerberos 126
KPI 10, 110, 113, 169
kubus 12, 160
L
Label Field 89
Language 60, 62
Layout-toolbar 66
lay-outvenster 178
Linked Reports 134
List Data Region 57, 103
Lookup 102, 114
LookupSet 102
M
Manage Cache Refresh Plans
130
managed service account 26
Manage Parameters 134
Manage Permissions 143
Manage Processing Options
131, 132
Manage Subscriptions 137,
139
Map 110
213
Aan de slag met Reporting Services 2012
Matrix Data Region 57, 107
MDX 13
multidimensionele database
12
Multiples 189
N
naamgevingsconventie 45
named instance 23
New Project... 43
NoRowsMessage 87
Now 86
Null Delivery 137
O
OLAP 1, 12
OLTP 1
OverwriteDatasets 121
OverwriteDataSources 121
P
page breaks 75
page headers en footers 64
PageNumber 68
page size 115
paginanummers 68
parameter 84
Defaultwaarde 86
Parameters collectie 85
Personal BI 145, 147
Perspectives 171
pie chart 106
Placeholders 67
Play Axis 189
Pop out 181
PowerPivot Gallery 39, 175
PowerPivot-veldenlijst 151
Power View 16
Preview 59
Processing Options 129
Property venster 59
publiceren 119
pull delivery 135
push delivery 135
Q
Query Designer 54
214
R
RDL 50
regional settings 61
RELATED 155
renderformaten 115
Report Builder 16
Report Builder 3.0 39
Report Data-venster 50
Report History 132
Reporting Services Configuration Manager 27
ReportItems-collectie 75
Report Manager 22
ReportName 67
Report Parameter Properties
85
Report Server Project 44
Report Server Project Wizard
44
Row Groups 72
Row Identifier 167
RowNumber 70
rs.exe 123
rsreportserver.config 33
RunningValue 76
S
Scatter Chart 187
scorecard 113
security 140
Selfservice BI 145, 147
service account 26
SharePoint Central Administration 35
slicers 152, 183
Snapshot 130
Snapshot Options 132
Solution Explorer 44
Sorteren op kolom 156
sortering 71
Sparkline 110
SQL Server Data Tools 25
SQL Server Installation Center
34, 35
staafdiagram 106
static members 99
stermodel 5
Stored Procedure 53
Sub Report 107
Subscriptions 135
SUM 164
Switch 70
T
taartdiagram 106
Table Behaviour 167, 169
Table Data Region 57
Tablix 58
Tabular Model 161, 162
TargetDatasetFolder 120
TargetDataSourceFolder 120
TargetReportFolder 120
TargetReportPartFolder 120
TargetServerURL 119
templates 102
textbox 59
Tiles 185
time-outs 133
ToggleItem 98
toolbox 57
TotalPages 68
TOTALYTD 165
trends 110
U
UserSort 72
V
Value Field 89
valuta 62
veldenlijst 153
Verbergen voor clienthulpprogramma’s 153
Views 54, 185
Visibility 98
W
Web Service URL 30
Windows Authentication 126
Y
Year 86
Over de auteur
Peter ter Braake is zelfstandig SQL Server docent/consultant. Hij is MCT sinds 2002 en
SQL Server MVP sinds begin 2012. Hij werkt met SQL Server Reporting Services sinds de
eerste release in 2004.
978 90 395 2721 4
123
9 *uklpdo#bxmxyv*
Aan de slag met Reporting Services 2012
Ook alle instellingen die u kunt kiezen
voor rapporten nadat ze in gebruik zijn
gekomen, komen aan de orde.
Dankzij de opgaven biedt het boek
voldoende mogelijkheden om te oefenen
en ervaring op te doen. Zo kunt u de
behandelde stof direct in de praktijk
toepassen.
Aan de slag met Reporting Services 2012 is
bedoeld voor studenten en professionals
die met Reporting Services gaan werken.
Voorkennis van Reporting Services is
niet noodzakelijk, maar kennis van het
Microsoft-platform is een pre. Daarnaast
is het in de praktijk onontbeerlijk om enige
kennis te hebben van SQL of als u met
kubussen wilt werken, van MDX.
ter Braake Microsoft SQL Server 2012 Reporting
Services is een uitgebreide tool om
rapporten mee te maken, te beheren en te
gebruiken. Het biedt vele mogelijkheden
en opties en is bruikbaar in zowel de
kleinste, alsook de grootste en meest
kritische omgevingen.
De beste manier om een uitgebreid
product zoals Reporting Services te leren
kennen is er actief mee te werken. Dit
boek is geschreven om u daarbij te helpen.
Stap voor stap wordt u begeleid bij het
installeren van Reporting Services en
vervolgens bij het maken van rapporten.
Bij alle keuzes wordt stilgestaan bij de
mogelijke opties en wanneer te kiezen
voor welke optie. Zo leert u al doende
goede en duidelijk rapporten te bouwen
en ze te gebruiken.
Aan de slag met
Reporting Services 2012
voor Microsoft SQL Server
Peter ter Braake