Spatial subgroup mining
Marlies Mooijekind
Overzicht
Spatial subgroup mining: spatial
patterns
SubgroupMiner
Spatial data
Spatial subgroups
Subgroup mining algoritme
Applicatie
Spatial subgroup mining
Subgroup: deelverzameling van een
populatie met bepaalde eigenschappen
– Werkeloosheid is hoog voor jonge mannen met
een lage opleiding
Subgroup mining: subgroups vinden waarvan
de target variabele afwijkt om afhankelijkheid
tussen target variabele en explanatory
variabelen te analyseren
Subgroup patterns
Deviation pattern: beschrijft subgroup
met een afwijking van target variabele
t.o.v. hele populatie
Association pattern: identificeert een
paar van subgroups waartussen en
associatie is.
Trend pattern: identificeert subgroups
met een trend in target variabele
SubgroupMiner
Subgroup mining systeem:
– multirelationale hypotheses
– efficiënte database integratie, deel van
zoek algoritme in spatial database system
(SDBS)
– visualisatie resultaten in GIS
Sterke punten SubgroupMiner
Data access:
– geen data transformatie, geen fouten
Geen Pre-processing:
– joins alleen berekenen wanneer nodig
Visualisatie:
– Visualisatie GIS en data mining gebruiken
dezelfde data
Representatie spatial data
Object-relational database
Spatial data base S: verzameling
relaties R1,…,Rn
– elke relatie Ri is gelinkt met een relatie Rk
via een geometrische attribuut Gi of een
attribuut Ai van Ri
Geometrisch attribuut Gi: geordende
verzameling x-y-coördinaten (punten,
lijnen, polygonen)
Representatie spatial data
Verschillende objecten (straten,
gebouwen) opgeslagen in verschillende
relaties Ri (geografische lagen)
Elke laag heeft verzameling attributen
A1,…,Am (thematische data) en
maximaal 1 geometrisch attribuut Gi
Querying multirelational spatial
data
Extra operatie spatial join
Linkt twee relaties op basis van hun
geometrische attribuut
Afstand of topologische relatie (disjoint,
overlap, covers, inside, intersect,
interacts)
Index structures (KD-trees, quadtrees)
voor efficiënt spatial joins
Pre-processing (1)
SDBS: multirelational met non-atomic
data types (punten, lijnen,polygonen)
Veel spatial data mining aanpakken:
singlerelational data met atomic data
types
Pre-processen: alle attributen die nodig
zijn in 1 tabel joinen met alleen atomic
data types
Pre-processing (2)
Nadelen:
– beperkt hypothese ruimte
– inefficiënt voor opslag en rekentijd:
onderzoekt hele hypothese ruimte
– overtollige data
Voordeel: sneller tijdens analyse
SubgroupMiner geen pre-processing:
tabellen dynamisch joinen, attributen
selecteren tijdens zoeken
Spatial subgroup
Subverzameling van analyse objecten
beschreven door een verzameling
expressies:
– operaties op de spatial referenties van
objecten
Voorbeeld: alle vegetatie records
dichtbij een rivier
– spatial predikaat minimum afstand op
coördinaten van objecten vegetatie records
en rivieren
Hypothesis language (1)
Multirelational subgroup:
– concept set C = {Ci}
– concept Ci = {Ci.A1=v1,…, Ci.An=vn}
C = { {records.river_distance=medium,
records.indigofera=3}, {soil.type=‘Ql11-1a’}
}
Hypothesis language (2)
Multirelational subgroup:
– set of links L = {Li}
– link Li = Cj.Am θ Ck.Al tussen twee concepts
Cj en Ck
– θ is ‘=‘, afstand, topologische relatie
(disjoint, overlap, covers, inside, intersect)
L = {{spatially_interacts(records.geometry,
soil.geometry)}}
SubgroupMiner
Integratie met spatial database
systeem:
– subgroups omschrijven in een query taal
– query uitvoeren op spatial database
– teruggekregen subgroups uit database
evalueren: hoeveel afwijking van target
variabele
Subgroups in query-taal
SQL:
– FROM: relaties (tabellen)
– WHERE: links en selectors (attribuutwaarde)
C = { {records.river_distance=medium,
records.indigofera=3}, {soil.type=‘Ql11-1a’} }
L = {{spatially_interacts(records.geometry,
soil.geometry)}}
Subgroup mining algoritme (1)
Iteraties van general naar specific
In elke iteratie:
– parents subgroups uitbreiden op allerlei
manieren
– gespecialiseerde subgroups evalueren
– nieuwe parent subgroups selecteren voor
volgende iteratie
Subgroup mining algoritme (2)
Subgroup uitbreiden: selector of link
toevoegen
Subgroup evalueren: quality function
gebaseerd op afwijking van target
variabele en (relatieve) grootte van
subgroup
Subgroup selecteren: quality hoog
Subgroup mining algoritme (3)
Stop criteria mining:
– maximum search depth
– geen enkele subgroup met hoge quality
Applicatie (1)
Analyse van vegetatie data van Nigeria
– 132 vegetaties records: 1 per site, elk
record beschrijft welke planten voorkomen
– terrein informatie: vorm oppervlak,
afwatering
– bodem informatie: graad van erosie,
inwortel diepte
– thematische lagen: rivieren, steden
Applicatie (2)
Doel is onderzoeken van geschikte
conditie voor het bestaan van een
plantensoort:
– ander plantensoorten
– ecologische condities: regenval, bodem
type
– niet-lokale condities: afstand tot rivier
Applicatie (3)
Resultaten
Target (T)
Subgroup (C)
P(T)
P(T|C)
Q
Phyllanthus=3
Cenchrus=3,
Eragostis=3
0.15
0.50
4.1
Merrimia=3
Jacquemontia=3,
Guiera=9
0.37
0.75
3.1
Applicatie (4)
Resultaten
Target (T)
Subgroup (C)
P(T)
P(T|C)
Q
Zornia=3
Cenchrus=3,
Village distance=low,
Isohyets Type=600
Isohyets Type=600,
Soil Type=Q11,
Soter Type=cc2
0.23
0.60
3.7
0.17
0.36
2.9
Ctenenium=3
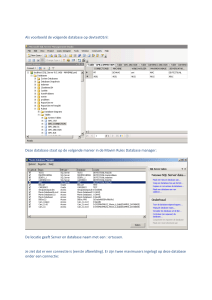
Visualisatie(1)
Visualisatie(2)
Plot P(T|C) tegen
P(T)
Conclusies
Subgroups
SubgroupMiner
– Database integratie
– Geen pre-processing
– Visulatie in GIS
Subgroup mining algoritme
Spatial joins duur: cach search results