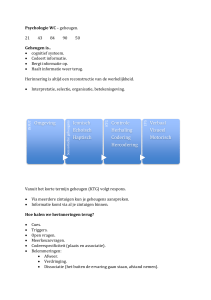
HOOFDSTUK 1 : COGNITIVE PSYCHOLOGY
De cognitieve psychologie laat zich het best herkennen door diens experimentele en
empirische aard. Vroeger was nadenken over geheugen vooral een taak van filosofen,
nu onderzoekt men (voor zover mogelijk) dmv experimenten. De definitie is:
The scientific study of thought, language and the brain
Door middel van zeer simpele vragen kan aangetoond worden dat veel mental
processes automatisch zijn en onbewust uitgevoerd worden. Memory en Cognition
zijn belangrijke termen:
Memory
The mental processes of acquiring and retaining information for later retrieval and the
mental storage system that enables thses processes.
Cognition
The collection of mental processes and activities used in perceiving, remembering, thinking
and understanding as well as the act of using these processes.
Cognition is een vagere term die feitelijk refereert naar alle hogere mentale
processen. Niet alle onderwerpen die op het eerste oog tot cognition horen worden
echter onderzocht.
Men is geinteresseerd in dagelijkse en normale cognitieprocessen. Kritiek op deze
keuze is:
1] de nadruk ligt sterk op visie en gehoor terwijl andere zintuigen niet erg onderzocht
worden.
2] het gebruik van steriele experimenten die een te simpel beeld geven (lage
ecological validity)
De laatste kritiek (Neisser) is van betrekking op het reductionisme van deze tak; het
ontleden van complexe processen in de delen. Argumenten tegen de kritiek van
Neisser:
1] de elementaire processen zijn zelf nog steeds zeer complex
2] het is aannemelijk dat wetenschappers uiteindelijk de stukken weer bij elkaar
kunnen brengen
>> HISTORY OF COGNITIVE PSYCHOLOGY1
Voor de geschiedenis van de cognitive psychology geldt:
Psychology has a long past but only a short history
De long past begint bij Aristotles die de basis legt voor de empirische wetenschap.
Hij beschrijft het geheugen als een netwerk van associations – een visie die nog geldt.
Bovendien is de geest voor hem een tabula rasa – een leeg vel papier waar nog niets
op geschreven staat bij de geboorte. Door ervaringen, via de zintuigen, wordt dit
papier langzaam gevuld (niet-nativistisch!).
Descartes ziet de rationele methode, nadenken en filosoferen, als de
wetenschappelijke methode. Deze wordt verworpen.
De psychology begint pas echt in de helft van 1800. De grootste denkers zijn:
Wilhelm Wundt (1832-1920):
Wundt leidde een boel bekende psychologen op in zijn aan de university of Leipzig. Hij
schreef tevens het eerste textboek over psychology: principes of psychiological psychology.
Wundt was zijn tijd vooruit, en veel van zijn theorieen worden pas nu weer erkend (zoals de
volker psychologie). Vooral Titchener vond dat Wundt zich met gebieden bezig hieldt die
1
Het schema op bladzijde 13 is zeer overzichtelijk en ik zou die zeker gebruiken bij het leren
volgens hem buiten de psychologie moesten vallen. Wundt maakte gebruik van
introspection om conscious processes and immediate experience te onderzoeken. Hierbij
werd gebruik gemaakt van goed getrained introspectors die stopten zodra bewuste
processen (mediate processes) ‘inbraken’.
Edward Titchener
Werd opgeleid door Wundt, maar ging naar de VS. Hij gebruikte ook introspection. Hij wilde
enkel onderzoek doen naar zaken waarbij dat mogelijk was (en sloot dus veel uit). Hij
onderzocht de structuur van het brein door naar diens meest elementen te kijken
(structuralisme). De introspectie-rondes werden door Titchener beoordeeld. En dat is dat
ook kritiek; het was niet echt een wetenschappelijke methode.
Hermann von Ebbinghaus
Ebbinghaus hieldt zich bezig met het geheugen. Hij geloofde echter dat mentale processen
best objectief onderzocht konden worden (niet dmv introspectie). Hij deed onderzoek bij
zichzelf met woordlijsten die hij probeerde te onthouden en de mate van recall mat. Zijn
invloed op de gebruikte methoden van tegenwoordig is enorm.
William James
James richtte zich op de functie van de geest (functionalisme). Hij hield niet erg van
onderzoek, en analyseerde meer. Hij was de eerste die het geheugen deelde in
componenten. Titchener bekritisteerde hem, maar het werk van James had uiteindelijk veel
meer invloed.
Rond 1910 (tot 1950) ontstond het behaviorisme onder leiding van Watson. Hij stelde dat
alles terug te voeren tot stimulus-response koppelingen en ontkende het bestaan van mentale
processen (antimentalism). De psychologie werd een scientific study of behaviour.
Het behaviorisme werd enthousiast ontvangen:
1] men was de subjectieve introspectie meer dan zat
2] men wilde graag lijken op andere wetenschappen en verlangde naar empirisch
onderzoek.
Verbal learning, het onderzoek naar hoe mensen verbaal materiaal onthouden, werd door
Ebbinghaus echter voorgezet. Maar zij werden met de nek aangekeken.
Skinner verzachte het extreme behaviorise door ruimte te laten voor de geest, maar die niet
te onderzoeken – ze waren niet belangrijk genoeg (neo-behaviorisme). Maar ineens sloeg
het echter om en werd behaviorisme vervangen. Redenen voor deze reactie:
World War 2
In WW2 werd duidelijk dat de psychologen geen praktische toepassingen hadden. Zij
hadden alleen ratten en wisten niet hoe om te gaan met geestelijke problemen. Ze
werden gedwongen de mens anders te bekijken. Men moest het gebied, en het
onderzoek, weer uitbreiden.
Verbal Learning
Deze onderzoekers werkten wel met de empirische methoden maar verwierpen
mentale processen niet. Zij onderzochten ze zelfs. De resultaten lieten iets zien wat
mentale processen alleen konden verklaren.
Linguistics
Chomsky publiceerde een paper als response op een boek van Skinner over het leren
van taal. Skinner had echter geen theorie voorgesteld. Hij maakte gebruik van allerlei
vage begrippen zoals reinforcement en zag taal als self-reinforcing. De verklaringen
waren dogmatisch en niet wetenschappelijk. Dit vormde een bijzonder krachtig tegen
het behaviorisme.
Nonlearned behaviors
Steeds meer onderzoek liet instincten zien – iets wat indruist tegen de tabula rasa
gedachte van het behaviorisme.
Rond 1960 begon de cognitieve psychologie. Bovenstaande redenen leidden tot diens
ontstaan. Men keerde terug naar de mentale processen. Steeds meer onderzoek (het
aandachtsexperiment van Broadbent) liet indirecte invloed van mentale processen zien. De
ontdekking van de computer speelde tevens een grote rol – het vormde een grote inspiratie
omdat het wel leek op hoe een mens leek te functionere.
De aannames van de cognitieve psychology:
Mental processes exist : mentale processen bestaan in de geest
Mental processes can be studied scientifically : ook al is het indirect
Humans are active information processors : mensen zijn geen passieve S-R machines.
Deze aspecten zijn metatheoretical – ze zijn zo elementair dat ze boven iedere theorie
uitgaan en niet bewezen kunnen worden, maar wel aangenomen worden.
HOOFDSTUK 2 : THE COGNITIVE SCIENCE APPROACH
De cognitive psychology kent een aantal aannames die het niet kan bewijzen, maar
waarop het voortbouwt; metatheorie. De grootste metatheorie was lange tijd de
information-processing die cognitie ziet als een gecoordineerde operatir van actieve
mentale processen binnen een multi componentaal systeem. De eerste varianten waren
serieel van aard (verwerking was serieel), maar werden later parallel. De nieuwe
cognitieve benadering komt mede uit de neurocognitie.
De zeven themas van cognition:
1] attention : een belangrijk maar niet goed begrepen proces
2] automatic vs conscious processing : sommige processen zijn automatisch
3] data-driven vs conceptually driven processing : interne vs externe informatie voor
processe
4] representation : hoe wordt data vastgelegd en is de gebruikte ‘code’ overal gelijk
5] implicit vs explicit memory : hoe beinvloeden onbewuste herinneringen ons gedrag?
6] metacognition : hoe werkt dit, en misleid het ons soms?
7] brain : de meer praktische vragen; waar wordt informatie vastgelegd, en hoe?
Onderzoek naar mental processes kan niet direct. 2 methoden worden veel gebruikt
Reaction time
Men meet de tijd die verstrijkt tussen de stimulus en de response. Men gaat ervan uit
dat deze processen tijd kosten en dat meet men. Die tijd kan men vervolgens trachten
te verklaren.
Accuracy
Men meet de nauwkeurigheid (bijvoorbeeld het aantal woorden dat men terug kan halen van
een woordlijst). Men kijkt ook naar de fouten die gemaakt zijn – waarom juist die fout?
Er zijn enkele analogieen die cognitief psychologen maken met de mens:
Channel capacity
Men stelt dat mensen een beperkte capaciteit hebben tot het verwerken van informatie. Dit
concept is geleend van electrotechnici.
Computer analogy
De ‘input’ van computerwetenschappen was gigantisch. De computer leek op de mens
(deels omdat die weer op de mens gebaseerd was). De verwerking van de mens wordt
als vergelijkbaar gezien met die van een computer:
1] het geeft inzicht in de mens
2] het maakt computer-modellen mogelijk van menselijk gedrag
3] die computermodellen, die geprogrammeerd worden, vereisen dat meen zeer specifiek is over hoe iets werkt.
>> THE INFORMATION PROCESSING APPROACH
Men gaat uit van de volgende standard theory of the human mind:
Sensory registers : met speciale geheugenregisters voor ieder type zintuig
Short-term memory : tijdelijke opslag met rehearsal, encoding, decisions en
retrieval strategies
Long-term memory : een langdurige opslag
Input komt vanuit de omgeving, middels het omzetten van de stimulus in een
bruikbare mentale vorm (encoding), en reist via het sensorisch geheugen naar het
werkgeheugen dat een response genegereerd op basis van informatie uit andere
geheugendelen. Men is zich bewust van informatie in het STM en raadpleegt het
LTM. Op basis daarvan wordt de response gevormd.
Lexicale decisietaken worden hier vaak gebruikt. Men meet hoe lang het duurt voor
een proefpersoon een woord te herkennen. Woorden die vaker voorkomen in de taal
worden sneller herkend (word frequency effect). Om de individuele mentale
processen, en hoe zij samenwerken, te beschrijven wordt gebruik gemaakt van proces
models (flowcharts).
Deze benadering was vroeger strikt - de strikte theorie hield aan:
Sequential stages of processing : de stappen volgen elkaar – niet tegelijkertijd.
Independent and nonoverlapping : processen moeten volledig ‘af’ zijn voordat het
verder gaat
Problemen met de strikte versie waren echter:
Parallel processing
Onderzoek liet parallele effecten zien. Zoals dat typisten tegelijkertijd typen en vooruit denken
over de karakters die ze gaan typen.
Context effects
Er spreek sprake te zijn van priming effecten. Dit betekent dat een eerder proces een later
proces beinvloedt. Dit kan niet volgens de seriele verwerking.
Methods and proces models
Een andere beperkingen was dat de nadruk op proces models leidde tot onderzoek naar zeer
simpele mentale processen en verwaarloosde de complexe processen die vele minuten
duren. De gebruikte RT-methoden werkten niet goed bij de langer durende processen. Hierbij
wordt tegenwoordig gebruik gemaakt van verbal protocol procedures waarbij de
proefpersoon zijn denkstappen toelicht.
>> THE MODERN COGNITIVE APPROACH
Tegenwoordig spreekt men liever over cognitive science daar men informatie uit vele
takken v/d wetenschap haalt. De hiervoor bespreken theorie is bovendien aangepast:
Parallel processing
De 3 geheugencomponenten zijn nu los van elkaar en kunnen dus taken, los van
elkaar, uitvoeren (blz 51). De oude analogie met de computer maakte het te
gemakkelijk om maar niet over het brein zelf na te denken, maar te proberen de
software te begrijpen en de hardware te negeren. De neuropsychologie liet zien dat
het allemaal niet zo gemakkelijk is.
Context
De 3 geheugencomponenten kunnen nu ook elkaar beinvloeden via 2-weg verbindingen.
Top-down en bottom-up processing is nu mogelijk in het model. Informatie die al aanwezig
in je LTM kan het zintuigelijk geheugen beinvloeden. Eerder opgedane kennis heeft een
invloed op vroegere of simpelere mentaler processen.
Fixing the narrowness
Men gebruikt nu veel meer technieken dan enkel RT- en nauwkeurigheids taken.
>> NEUROCOGNITION : THE BRAIN AND COGNITION TOGETHER
Dissociation is de verstoring van één geheugenelement terwijl een ander component
blijft werken – dit duidt op onafhankelijkheid. Bij een double dissociation zijn beide
delen volledig onafhankelijk van elkaar (werkt beide kanten op). Veel kennis is
afkomstig van mensen met hersenbeschadigen. Het gebied dat hier onderzoek naar
doet wordt vaan cognitive neuropsychology genoemd. Een breder gebied is echter de
neurocognition die zich bezig houdt met de neurowetenschap van de cognitie.
Hersenbeschadigingen zijn dus erg interessant.
>> NEUROLOGY
Het CNS bestaat uit neuronen – cellen gespecialiseerd in het overbrengen/ontvangen
van zenuwpulsen. Er zijn ongeveer 80 miljard aanwezig. Een neuron heeft
dendrieten, een soma, en een axon met daaraan een axon terminal (of meer
vertakkingen).
Bij het raken van iets heets door een receptor cel gaat een puls via sensory neurons
naar de ruggengraat en weer terug naar een motor neuron die een serie effector cells
in de spieren laat bewegen. Tevens gaat er een signaal, via interneurons /
associationneuron in de ruggengraat, naar het brein.
Synapsen scheiden neurotransmitters af die andere neuronen exciteren (type I) of
inhiberen (type II). Een neuron is altijd maar van 1 type, en kent niet zowel type I als
II synapsen. Er zijn ong 30 soorten neurotransmitters waarvan een deel nagebootst
kan worden door andere stoffen (drugs).
Het brein bestaat uit the old brain of brain stem en de neocortex of cerebral cortex
die later in de evolutie gevormd is. De neocortex bestaat uit lobes die genoemd zijn
naar de schedelplaten waaronder ze liggen (van voor naar achteren):
De pre-frontal lobe.
De frontal lobe
De central sulcus
De postcentral gyrus
De parietal lobe
De occipital lobe
De temporal lobe (onderkant – bij de ‘slapen’ in het engels ‘tempels’ genoemd)
In het brein zelf liggen een aantal andere delen:
Thalamus : het relay station van het brein. (bijna) alles dat naar de cortex gaat komt hierdoor
Hippocampus : van belang bij geheugen
Corpus callosum : verbindt beide hersenhelften met elkaar.
Het brein is gelateraliseerd, wat betekent dat bepaalde functies specifiek door
bepaalde delen worden uitgevoerd. Deze verdeling is echter niet heel strikt (let daar
op – het is niet zo simpel als in Kalat staat). Dit geldt voor rechtshandigen:
Rechts: Voor alle meer abstracte en emotionele zaken
Links: Voor concretere en taal-gerelateerde zaken.
Het brein is contralateraal in dat het het tegenovergestelde deel van het lichaam
bestuurt.
Split-brain patienten vormen een goede bron voor onderzoek. Een patient kreeg een
pen in zijn rechterhand, kon er wel mee schrijven, maar kon het niet benoemen.
Er zijn meer methoden van onderzoek om het brein te verkennen:
Lesions :
Mag alleen bij dieren of mensen met hersenbeschadigingen. Men beschadigd het brein
(of kijkt naar al aanwezige schade) en probeert te bepalen wat de gevolgen daarvan
zijn.
Direct stimulation
Men stimuleert delen tijdens hersenoperaties. Het is echter lastig onderzoek omdat het
een klinische omgeving is en omdat de behandelen vaak een abnormaal brein hebben.
Imaging technology
Met magnetic resonance imaging (MRI) en positron emition tomography (PET) kan
men het brein bekijken zonder het te openen. Men kan hiermee ook functional scans
maken waarbij het brein bekeken wordt bij het uitvoeren van een bepaalde taak
(fMRI). Men meet de bloedtoevoer, en het probleem daarvan is dat die vaak achter de
zaken aanlopen daar de extra bloedtoevoer even op gang moet komen.
Electroencephalograms & event-related potentials
Men meet de electrische activiteit. P600 staat voor ‘600 microseconden na stimulus’.
Het kan niet goed laten zien waar de taak uitgevoerd wordt, maar wel wanneer.
>> NEURAL NET MODELS (CONNECTIONISM)
Dit betreffen computer-based techniques for modeling complex systems. Ze gaan uit
van elementaire eenheden die interacteren om een complexer iets mogelijk te maken.
Bovendien werken ze parallel (zie blz 71). Dit model lijkt veel op de werking van het
brein, met diens losse neuronen die daar de elementaire units vormen. Deze modellen
kunnen goed dmv zeer krachtige computers nagebootst worden.
HOOFDSTUK 5 : SHORT TERM MEMORY
Het short term memory (STM) heeft vele namen, waaronder working memory en
primary memory. Het is het deel van het geheugen waar informatie over heden is; we
zijn ons bewust van de informatie die zich hier bevindt. De vroegere term, short-term
memory, blijkt echter te krap en is later vervangen door working memory (WM).
>> SHORT-TERM MEMORY
Het STM is als een bottleneck tussen het sensorisch (SM) en long-term (LTM)
geheugen; het kent een beperkte capaciteit. Het kan ongeveer 7 items bevatten, plus of
minus 2 (Miller). Om de bottleneck te bedwingen kunnen mensen informatie
chunken; losse items groeperen in betekenisvolle chunks. Het proces waarbij
elementaire items worden opgenomen in betekenisvolle chunks wordt recoding
genoemd. In plaats van de elementaire items worden de groepen onthouden (zoals
woorden ipv losse letters). Dit kost echter wel attention.
Er zijn twee condities van belang voor recoding:
1] er is voldoende tijd nodig om de strategie om te recoden toe te passen
2] de strategie om te recoden moet goed aangeleerd zijn óf zelfs automatisch
gebeuren
Een strategie voor recoding óf herhaling wordt een mnemonic device genoemd. Zowel deze
device als de feiten komen terecht in het LTM. Meest gebruikt is het omzetten in verbale
code; we verwoorden iets in onze eigen woorden.
De brown & peterson task bestaat uit het leren van ee 3-letter stimulus gevolgd door een 3cijferig nummer van welke de proefpersonen terug moesten tellen in stappen van 3 waarna ze
de 3-letterige stimulus weer moesten opnoemen. De performance daalde hier en dat werd
door Brown en Peterson verklaard door decay; het vergeten van informatie over de (korte)
tijd.
Men vond echter een betere verklaring in interference; de distractor task interfereerde in het
geheugen met de woordlijst. Er zijn twee soorten interference (Wickens):
Proactive (PI) : eerder geleerd materiaal interfereert met het herinneren van nieuwere
informatie
Retroactive (RI) : nieuw geleerde informatie interfereert met eerder geleerde informatie.
PI treedt op bij het leren van nieuwe informatie door oude informatie. Hier is echter sprake
van als de nieuwe informatie van eenzelfde semantische categorie is. Indien de categorie
geheel anders is, dan verdwijnt de PI direct: release from PI.
>> SHORT-TERM MEMORY AND RECALL
Rehearsal is het proces waarmee informatie in het STM blijft. Informatie kan uit het
geheugen gehaald worden middels free recall (non-specifieke volgorde) en serial
recall (in volgorde van leren). Men kan recall goed testen door woordlijsten te laten
leren en op te laten noemen. Men kan een serial position curve opstellen waarin
aangegeven wordt hoe nauwkeurig de recall is van item tot item2.
Er treden bij woordlijsten typen effecten op:
2
ik zou eens kijken op blz 172 om voorbeelden te zien.
Primary effect : de nauwkeurigheid in het opnoemen van de eerste items in de lijst
Recency effect : de nauwkeurigheid in het opnoemen van de laatste items in de lijst
Het recency effect is gebaseerd op het STM. De laatste gehoorde woorden kunnen
snel weer opgenoemd worden. De eerste woorden vereisen het LTM om ze terug te
halen. De manier waarop de woorden teruggehaald moeten worden beinvloed de
resultaten:
Free recall : men leegt eerst het STM en herinnert daarna ‘at random’ wat men nog weet
Serial recall : het STM kan niet eerst geleegd worden – geen recency effect.
Het STM wordt gezien als een rehearsal buffer – een systeem waar informatie mentaal
wordt herhaald.
>> RETRIEVAL FROM SHORT-TERM MEMORY
Hoe raadplegen we informatie uit het korte-termijn geheugen? Dit kan men
onderzoeken middels recognition taken waarbij woorden herkend moeten worden.
Sternberg ontwikkelde de sternberg taak waarbij proefpersonen een aantal letters of
cijfers te zien, gevolgd door een probe (enkele letter of cijfer) waarbij aangegeven
moest worden of die in de stimulus voorkwam.
Sternberg gebruikte een proces model voor het herkenningsproces en maakte één van
de processen, het scannen van het geheugen, steeds moeilijker door het aantal
karakters in de stimulus te vergroten. In de resultaten werd een y-intercept zichtbaar
die aangaf hoe lang de overige processen in beslag namen, waarbovenop een
variabele tijd kwam die afhing van de lengte van de stimulus – deze groei was lineair.
Sternberg gaf drie mogelijke verklaringen:
Serial Self-terminating Search
Het STM wordt serieel doorzocht. Item-voor-item totdat het item gevonden is. Echter,
bij probes die niet voorkwamen in de stimulus duurde het zoeken even lang – men
zou juist verwachten dat die dan langer duren daar het gehele STM doorzocht moet
worden.
Parallel Search
Het STM wordt parallel doorzocht. Alle items tegelijk. Niet plausibel, want dan zou er geen
lineaire toenemende curve moeten zijn – die zijn dan gewoon vlak moeten blijven.
Serial Exhaustive Search
Het STM wordt steeds serieel doorzocht. Voor ieder item wordt het gehele geheugen volledig
doorzocht – zelfs als het item al gevonden is.
Later betwijfelde men echter:
1] Of fasen wel serieel plaatsvinden en elkaar niet deels overlappen
2] Of parallele search niet gewoon steeds langzamer wordt bij meer parallele
processen
>> MULTIPLE CODES IN SHORT-TERM MEMORY
Er zijn meere typen manier waarop herinneringen in het STM worden vastgelegd:
Verbal codes
De meest vroegere onderzoeken gingen ervan uit dat herinneringen verbaal vastgelegd
worden. Dit is meestal een acoustic-articulatory code omdat zowel de klank als de
uitspraak als ‘trigger’ kunnen dienen om de herinnering op te roepen. Dit komt echter
wel het meeste voor.
Semantic codes
Later bleek dat herinneringen ook semantisch vastgelegd worden en dus rekening houden
met de categorie waartoe iets behoort. Dit is middels release from PI tests gedaan. Zodra een
woord tot een andere categorie behoorde werd eerdere PI ineens ongedaan gemaakt wat
duidt dat ook rekening gehouden wordt met de semantische betekenis.
Visual codes
Studies waarbij proefpersonen plaatjes in gedachten mentaal moesten roteren lieten zien dat
herinneringen ook visuel vastgelegd worden. Hoe kan men een zeer complex plaatje ooit
onthouden middels de andere codes?
Other codes
Er zijn nog meer codes; zoals doventaalcodes, ens.
>> WORKING MEMORY
In de visual code experimenten (mentale rotatie) bleek al dat het STM eigenlijk meer
een sorot werkbank van het geheugen is. De eerdere betekenis was te simpel; er waren
zeven (+/- 2) slots waar data in paste. Maar het STM bleek veel meer te doen.
Dit werd al snel duidelijk door neuropsychologisch onderzoek. Bij sommigen was de
digit-span slechts 2 cijfers groot (korte STM), maar toch konden ze complexe
gedachten en berekeningen bevatten. Het STM is slechts een deel van working
memory.
Baddeley onderscheidt de volgende componenten in het working memory:
Central Executive
De central executive vormt het belangrijkste deel. Het is de leider en de coördinator. Het plant
toekomstige acties, initieert het ophalen van herinneringen uit het LTM en integreert de
informatie die uit delen van het geheugen komen. Het kent 2 Slave Systems:
Articulatory / Phonological Loop
Het geluid- en spraak-gerelateerde component dat verantwoordelijk is voor de herhaling van
verbale informatie of fonologische verwerking. Het blijft auditieve informatie constant
herhalen.
Visuospatial Sketchpad
Een systeem dat gespecialiseerd is voor visuele en spatiele informatie alsmede het
vasthouden van dat soort informatie in een soort korte-duratie buffer.
De Slave systems kennen drie beperkingen:
1] Ze zijn verantwoordelijk voor lage processen. Hogere processen zijn voor de CE.
2] Ze zijn domein-specifiek en gespecialiseerd in speciale typen informatie (auditief/visueel)
3] ze hebben een beperkte pool met attention resources
Indien de taak zwaar is voor het slave system, dan moet het resources van de CE gaan
gebruiken. Dit kan men onderzoeken middels dual task methods.
De dual-task taak presenteert een proefpersoon met twee taken die hij/zij tegelijkertijd moet
uitvoeren. Als de taken elkaar niet storen, worden ze kennelijk door andere componenten
uitgevoerd. Doen ze dat wel; dan worden ze door hetzelfde component verwerkt of maken
gebruik van dezelfde resource pools:
Zware auditieve taken : halen veel resources van de CE en beperken diens snelheid
Zware visuele taken : halen veel resources van de CE en beperken diens snelheid
Verschillende domeinen : weinig verlies van performance, maar veel als die wel gelijk zijn.
Recent neurologisch onderzoek doet vermoeden dat de componenten van het WM in
verschillende hersengebieden gelocaliseerd zijn:
Central Executive : Bevindt zich in de dorsolateral prefrontal cortex (DLPFC)
Phonological loop : linkerkant v/d voorkant v/h brein, met name broca’s area
Visuospatial sketchpad : rechterkant v/d voorkant v/h brein
Een andere vorm van onderzoek is het bekijken van individual differences.
Proefpersonen krijgen eerst een test om de capaciteit en de snelheid van het
werkgeheugen te meten en dan een andere taak. Er zijn veel positieve correlaties met
leessnelheid, IQ en tekstbegrip. Dit komt mogelijk omdat mensen met een lagere
capaciteit feitelijk meer problemen hebben met het richten van de aandacht en het
inhiberen van andere signalen.
HOOFDSTUK 6: EPISODIC LONG-TERM MEMORY
Het LTM heeft geleid tot een groot onderzoeksgebied. Squire onderscheidt een
aantal delen:
Declarative (explicit) : de bewuste herinneringen die vaak ook bewust opgeroepen worden
Nondeclarative (nonexplicit) : de niet-bewuste herinneringen met invloed op gedrag
en denken
Het declaritive memory wordt onderverdeeld in:
Episodic memory : autobiografische herinneringen over je eigen leven
Semantic memory : generale kennis van de wereld
Mnemonic devices zijn leerstrategieën. Er zijn een tweetal bekende manieren:
Method of loci
Leren door begrippen te verbinden aan ‘locaties’ die je tegenkomt als je door de universiteit of
door huis loopt.
Peg word mnemonic
Een eerder geleerde set woorden (bijv de maanden v/h jaar) worden verbonden aan de te
leren begrippen door tussen de bekende woorden en de te leren woorden verbindingen te
verzinnen.
Mnemonic devices voldoen aan drie principen:
1] ze bieden een structuur voor de te leren informatie (acquistion)
2] dmv associaties ervaren begrippen minder last van interferentie (encoding)
3] het maakt het mogelijk effectieve retrieval cues te ontwikkelen (retrieval)
Ebbinghaus was de eerste die onderzoek deed naar het geheugen. Hij was zijn tijd ver
vooruit en ontwikkelde de methode, de benodigde statistiek (soort t-test) en de empirische
grondslag zelf. Hij leerde lijsten met nonsense syllabus (onzinwoorden) om het leren van
volstrekt nieuwe informatie te onderzoeken. Ebbinghaus herleerde de lijsten totdat hij ze
perfect kon herhalen, legde ze naast zich neer en leerde ze later opnieuw en bepaalde
hoeveel sneller hij de lijst nu foutloos kon leren. Het was een relearning task waarbij de
savings-score van lijst-tot-lijst wordt bepaald3. Het vaker herhalen van de lijst tijdens het
leren maakte dat de herinnering beter bleef hangen.
De impact van Ebbinghaus was groot, maar hij onderzocht slechts nonsense woorden en
hield geen rekening met de betekenis bij het leren. Maw; hij probeerde mnemonic strategies
te beperken. Tegenwoordig onderzoekt men juist die strategieen ipv ze te blokkeren.
De huidige positie kent drie delen:
1] mensen zoeken betekenis in het materiaal, zelfs als men dat probeert te voorkomen
2] proefpersonen zijn actief – ze gebruiken allerlei strategieen om te leren
3] onderzoek baseren op nonsensewoorden is vreemd – men wil juist leren hoe mensen leren
We hebben altijd gedacht over ons eigen denken: metamemory. Dit behoort tot
metacognition; het denken over je eigen cognitieve functioneren. Dit kent tenminste twee
belangrijke aspecten:
1] leren gaat altijd samen met self-monitoring en metacognitive awareness
2] mensen stellen het leren bij zodra ze merken dat de technieken niet goed werken
>> STORING INFORMATION IN EPISODIC MEMORY
Er zijn drie manieren om informatie vast te leggen in het LTM:
1] rehearsal : het herhalen van informatie
2] organization : het inbedden van informatie in een hierarchisch netwerk
3] imagery : het visualiseren van de informatie
3
Zie blz 211 voor een grafiek met de resultaten – natuurlijk leerde hij de lijsten steeds sneller
>> STORING INFORMATION IN EPISODIC MEMORY (REHEARSAL)
Volgens Atkinson & Shiffrin is rehearsal het actief herhalen van informatie in het
STM. 2 effecten:
1] de herhaling voorkomt dat andere informatie het overschrijft of dat het kwijt raakt
2] de herhaling zorgt ervoor dat het ook opgeslagen wordt in het LTM
Er worden 2 typen rehearsal onderscheiden:
1] maintainance (type 1) : passieve herhaling zonder te proberen het te begrijpen
2] elaborative (type 2): actieve herhaling waarbij het om de betekenis van iets gaat
De laatste vorm zorgt ervoor dat informatie veel dieper in het geheugen opgeslagen
wordt.
Er zijn typen taken om onderzoek te doen naar de effecten van rehearsal:
Relearning task
Men leert een lijst, wacht even, en leert de lijst opnieuw.
Paired-associate learning
Men leert een lijst met woordparen en legt vervolgens 1 van de woorden uit het paar voor met
de vraag het andere woord te geven van het paar.
Recall task
Men leert een lijst, wacht vervolgens of wordt afgeleid, en moet dan de lijst opnieuw
opnoemen.
Recognition task
Men leert een lijst en wordt vervolgens gevraagd of item X wel of niet voorkwam op de lijst.
Craik & Lockhart stelden een depth processing theorie op die stelde dat het
geheugen uit lagen bestaat4. Stimuli die meer bewust verwerkt worden, en dus meer
tijd van mentale processen krijgen, worden dieper vastgelegd en beter onthouden.
Elaboritive rehearsal werkt dus veel beter volgens deze theorie. Kritiek was echter:
Circulatory reasoning
Men kon alleen vaststellen dat er sprake was van elaborative rehearsal als informatie
werkelijk beter onthouden werd (higher recall), maar dat werd ook gebruikt als
bewijs dat elaborative rehearsal leidt tot higher recall.
Task effects
De theorie werd enkel onderzocht dmv recall tasks. Bij recognition tasks bleek dat
zelfs zeer kort verwerkte stimuli toch later ook herkend werden door de
proefpersonen. Het was het soort taak dat de resultaten beperkte; type 1 rehearsal had
wel degelijk effecten op de inhoud van het LTM.
>> STORING INFORMATION IN EPISODIC MEMORY (ORGANIZATION)
Organization is een belangrijk onderdeel van leren. Informatie wordt
geherstructureerd terwijl het opgeslagen wordt in het geheugen. Men ontdekte dat
mensen automatisch indelen in categorieen; het eerste bewijs voor hierarchieen in het
geheugen. Organization wordt als elementair gezien voor het geheugen. Mnemonic
devices bieden een vorm van organization.
Het besef dat organization zo belangrijk was vormde de brug naar het latere
semantische netwerk model van het geheugen. Er kwam ineens heel veel onderzoek
naar omdat:
1] Het paste goed met andere theorieen; het was een vorm van recoding mbv chunking
2] er was gemakkelijk en objectief onderzoek naar te doen
4
deze theorie is dus geheel anders dan die van Baddeley: SM, STM & LTM
Onderzoeken werden cluster research genoemd en betroffen meestal lijsten met
hierarchisch gestructureerde woorden of woorden in een willekeurige volgorde. Men
mat de nauwkeurigheid bij de recall; de hierarchische lijsten scoorden veel hoger.
Zelfs als categorieen niet door onderzoekers aangegeven worden, dan vormen
proefpersonen ze zelf wel: subjectieve categories.
>> STORING INFORMATION IN EPISODIC MEMORY (IMAGERY)
Dit betreft de mentale representatie van een stimulus. Piavio deed hier onderzoek naar
en stelde de dual coding hypothesis op. Hij stelde dat we beter leren als we een
woord verbaal leren, maar ook visueel proberen voor te stellen. Dat kan overigens niet
bij abstracte woorden (die geen directe verbeelding mogelijk maken). Dit heeft Piavio
onderzocht middels paired-associate learning waarbij pp’s gevraagd werd de
woordparen te visualiseren. Hier geldt echter de encoding specifity; de context
waarin iets geleerd heeft beinvloedt de latere recall. Deze contextuele informatie kan
later een retrieval cue vormen.
Dit werd aangetoond door pp’s een woord-foto paar te laten leren en ze daarbij
specifiek op het woord of op de foto te richten (‘onthoud de foto’ of ‘onthoud het
woord’). Prestaties waren het beste als ze later een deel van de foto te zien kregen als
ze op de foto hadden gelet of een deel van het woord als ze op het woord hadden
gelet.
>> RETRIEVING EPISODIC INFORMATION
Er zijn twee globale theorieen die aangeven waarom informatie soms niet opgehaald
kan worden:
Decay theory
Deze theorie stelt dat informatie over de tijd langzaam vervaagd. Alhoewel deze theorie nog
wel aanhangers kent, is het empirisch niet aan te tonen. Je kunt niet voorkomen dat pp’s
tussen het leren en recallen geen last hebben van interfererende effecten.
Interference
Informatie interfereert in het LTM met elkaar. Proactief als oudere informatie stoort bij het
aanleren van nieuwe informatie. Retroactief als nieuwe informatie de recall van oudere
informatie stoort.
Interferentie wordt onderzocht middels paired-associate learning. Men laat de
proefpersoon een lijst met woordparen leren en geeft vervolgens een lijst met óf
volledig andere woordparen óf een lijst met woorden uit de paren gekoppeld aan
andere woorden. In het laatste geval is de interferentie erg sterk (proactief). Ook kan
men een lijst geven waarbij één woord uit ieder paar steeds vervangen is door een
woord dat een hogere semantische categorie behoort (‘tak’ en ‘boom’ of ‘wiel’ en
‘auto’). In dit geval zal er sprake zijn van positive transfer daar de woordparen wel
anders zijn, maar sterk gerelateerd zijn.
De behavioristen zagen P-A learning slechts als het vormen van stimulus-response
relaties. Men hield geen rekening met de betekenis van een woord.
Huidige theorieen stellen dat informatie nooit verdwijnen, maar dat het moeilijker
wordt ze terug te halen. De tip-of-the-tongue is hier een goed voorbeeld van. Je bent
een woord kwijt, maar weet nog wel hoe lang het ongeveer was, hoe het klonk en wat
het in ieder geval niet was. Informatie is dus altijd available maar niet altijd
accessible.
Een goede retrieval cue vormt de context waarin iets geleerd is (encoding specifity).
De accessibility wordt verhoogd door effectieve retrieval cues.
>> AMNESIA AND IMPLICIT MEMORY
Amnesia is het kwijtraken van herinneringen door hersenschade of ziekte. Er zijn 2
typen:
Retrograde : herinnering van gebeurtenissen van voor het incident is onmogelijk
Anterograde : herinnering van gebeurtenissen van na het incident is onmogelijk
Mensen met amnesie kunnen laten zien hoe geheugen-delen zich tot elkaar
verhouden. Men kan een patient hebben die geen episodisch geheugen meer heeft,
maar nog wel een impliciet geheugen heeft. Hier is sprake van een dissociation daar
schade aan de eerste niet leidt tot disfunctioneren van de tweede. Als nu een patient
gevonden wordt die het tegenovergestelde heeft, en waarbij schade aan het impliciet
geheugen niet leidt tot disfunctioneren van het episodisch geheugen, dan is er sprake
van een double dissociation.
Een patient genaamd K.C. had geen episodisch geheugen meer. Hij kon geen
gebeurtenissen van voor óf na het incident terughalen. Zijn semantisch geheugen
werkte echter nog wel en hij had dus nog wel kennis van de wereld. Beide typen
geheugen berusten dus op andere delen van het brein. Dit kan ook aangetoond worden
dmv scans die de activation van hersendelen bij taken meten:
Episodic : frontal lobes
Semantic : posterior regios van het het brein
Een patient genaamd H.M. had anterograde amnesie en kon zich niets van na het
incident herinneren. Zijn impliciete geheugen werkte echter nog wel goed en hij kon
bepaalde procedurele taken aan leren (spiegelbeeld tekenen). De overdracht van
informatie van het STM naar het LTM was bij deze patient gestoord. De
hippocampus speelt hier een grote rol in.
Er is dus een verschil tussen implicit en explicit memory. Repetition priming is hier eveneens
bewijs van. Onbewust kan het zien van één woord een ander woord primen zonder dat je je
daarvan bewust bent. Hier had Ebbinghaus totaal geen aandacht voor, en het is dus maar
goed dat dat er nu wel is.
HOOFDSTUK 7: SEMANTIC LONG-TERM MEMORY
Het semantic memory bevat onze generieke kennis van de wereld. Collins &
Quillian stelden het eerste model op over dit geheugen. Zij gebruikten hierbij een
door Collins ontwikkelt computerprogramma dat ontwikkeld was voor taalbegrip als
basis. Zij zagen:
Structuur
Het betreft een netwerk waarin nodes, locaties of plekken in dat netwerk, met elkaar
verbonden zijn via pathways.
Proces
De activatie van een node leidt tot activatie, middels de pathways, van nabijgelegen
nodes (spreading activation).
In het netwerk kunnen meerdere activaties tegelijkertijd plaatsvinden. Zodra deze
gebieden van activatie elkaar bereiken (intersection) wordt door een decision stage
bepaald of de relatie tussen de twee begrippen correct is (is ‘alle vogels kunnen
vliegen’ een gerechtigde uitspraak? De beide concepten ‘vogels’ en ‘vliegen’ worden
geactiveerd in het netwerk). Bovendien worden related concepts geactiveerd
(geprimed).
Nodes kunnen op verschillende manieren gekoppeld zijn:
Proposition : een node behoort tot een andere node (categorie lid : vogel duif)
A
IS
Property : een node kent een node als eigenschap (object eigenschap : duif
vleugel) P
Smith stelde een ander model op: het feature comparison model. Hij zag het
geheugen als bestaande uit lijsten waarop semantic features van concepten beschreven
werden; feature lists. Deze features waren simple, one-element characteristics or
properties of the concept. Volgens Smith zijn deze features op deze manier
gesorteerd in de lijsten:
1] definining features : de meest elementaire en belangrijke eigenschappen komen eerst
2] characteristic features : niet-essentiele, maar wel belangrijke eigenschappen
komen later.
Volgens het model van Smith wordt een zin (bijv ‘een duif is een vogel’)
gecontroleerd door de lijsten van zowel ‘duif’ als ‘vogel’ inhoudelijk met elkaar te
vergelijken. Als de global features sterk overeen komen (of niet), dan is de keuze snel
gemaakt. Is het verschil vager, dan worden ook de defining features met elkaar
vergeleken – dit duurt langer. Dus: feature comparison als basis.
Om beide modellen te testen is veel gebruik gemaakt van sentence verification taks
waarbij proefpersonen een zin moeten beoordelen (‘kat is een dier’). Beide modellen
voorspelden dat meer gerelateerde concepten sneller beoordeeld konden worden – dit
klopte.
Onderzoek richtte zich op:
Cognitive economy
Het model van Collins & Quillian impliceerde dat concepten één maal voorkwamen
en niet vaker in het netwerk aanwezig waren. Een concept kon mede profiteren van de
eigenschappen van hoger-gelegen concepten (inheritance) waardoor redundantie niet
nodig was5. Uit onderzoek bleek dat minder direct gerelateerde begrippen meer RT
kostten. Dit werd gezien als bewijs voor de inherentie stappen. Toch bleek uit later
onderzoek dat informatie wel redundant kan zijn. De RTs uit het eerdere onderzoek
kwamen voort uit het feit dat de pathway tussen 2 direct gerelateerde begrippen
gewoon zwakker was.
Property statements
Een probleem met het model van Smith was dat het niet om kon gaan met vagere concepten
zoals ‘een kanarie is geel’. Dit zou een lijst vereisen voor ‘dingen die geel zijn’ en dat leek
zeer onlogisch. Het model van Collins & Loftus (aanpassing) had daar geen problemen
mee.
Typicality
In hoeverre is een item een typisch, centraal lid, van een categorie? Indien een item meer
typical is voor een categorie, dan gaat de beoordeling sneller (typicality effect):
‘is een duif een vogel?’ gaat sneller dan ‘is een penguin een vogel?’
Een aangepaste vorm van het model werd opgesteld door Collins & Loftus. Verwerkt
werden:
No cognitive economy : begrippen kunnen vaker voorkomen binnen het netwerk
Typicality : typische leden van een categorie liggen dichterbij de categorie in het netwerk
Importance of properties : eigenschappen die belangrijker zijn voor een concept, liggen
dichterbij
Het geheugen is geen hierarchisch model waarbij lager gelegen items eigenschappen van
hogere items altijd inheriten. Concepten die meer gerelateerd zijn worden sneller gekoppeld
(semantic relatedness effect).
Een krachtig tegenargument is gekomen uit fysiologisch onderzoek waarbij men niet de RT,
maar de electrische potentialen meet (event-related potentials - ERP). Uit dit onderzoek
blijkt dat het zoeken door het netwerk zelf niet het verschil in RT veroorzaakt, maar het
proces dat moet beslissen of de gevonden koppeling wel of niet correct is.
>> CATEGORIZATION, CLASSIFICATION AND PROTOTYPES
Er is tevens veel onderzoek gedaan naar hoe die semantich relationship tussen
concepten nu eigenlijk gemaakt wordt. Hoe vormen wij categorieen? In eerste
instantie ging men uit van zeer strikte categorieen, maar nu gelooft men dat die
categorieen juist heel vaag zijn. De eerdere categorieen waren artificieel, iets was wel
of geen lid. Maar onze categorieen zijn natuurlijk, een item kan meer of minder tot
de categorie behoren (Rosch).
Categorieen kennen volgens Rosch een prototype; een centrale, kern-voorbeeld van
die categorie. We delen in op basis van deze prototypen waarbij items die hier meer
op lijken ook beter tot de categorie behoren6.
>> PRIMING IN SEMANTIC MEMORY
Een prime activeert een deel van het netwerk, en maakt de target daarmee meer of
minder toegankelijk voor mentale processen (respect. facilitation of inhibition).
Interessant is dan:
Priming across trials
Men presenteert een prime, vervolgens een X-aantal andere stimuli (lag tussen prime
en target), en dan de target en bepaalt of er nog een faciliterend effect optreed. Zo
meet men de duur van de activatie van het netwerk.
Priming within trials
Men presenteert een prime en vervolgens een target. De prime is related, unrelated of
neutral en meet hoe snel de prime en de target als woorden gekeurd worden in een
5
6
een vogel vliegt, dus een duif, een vogel, vliegt ook – vliegen hoeft niet ook bij duif opgenomen te worden’
een ‘duif’ is een beter voorbeeld van het prototype van een vogel dan een penguin of een struisvogel
lexicale decisietaak. Men kan de periode tussen de prime en de target varieren
(stimulus onset asynchrony - SOA).
Uit onderzoek blijkt dat de categorie een betere prime is voor een item dan andersom.
Bovendien verhoogde een langere SOA de reactiesnelheid omdat het netwerk langer kon
profiteren van een zich verspreidende activatie. Een langere lag (meer dan 0 – geen lag) liet
een kleine faciliterende werking zien.
In een lexical taak moet de proefpersoon bepalen of twee woorden wel of geen
geldige woorden zijn. Dit proces gaat sneller als het eerste woord het tweede primed.
Deze priming gebeurt op semantisch niveau – op betekenis. Een woord ‘NURSE’
primed ‘DOCTOR’. We zoeken dus automatisch de betekenis op. Priming deels
automatisch – impliciet en deels handmatig. Het automatische deel vind eerst plaats,
maar kan vervolgens gemanipuleerd worden7. Het model van Smith kan priming niet
verklaren.
7
het experiment van Neely (blz 284) laat dit goed zien maar is hier lastig uit te leggen – lees het zelf wel door.
>> CONTEXTS, CONNECTIONISM AND THE BRAIN
De context van iets dat we lezen of zien vormt een prime. Dit bleek ook uit ERPonderzoek waarbij proefpersonen een zin woord-voor-woord te zien kregen. Zodra de
zin eindigde met een totaal niet verwacht woord (niet in de context) lieten de
resultaten andere pieken zien.
Connectionisme, PDP-models of neural net models vormen een voorbeeld van hoe
mentale processen kunnen werken. Ze leveren geen bewijs dát het zo werkt, maar wel
dat de theorie overeen komt met wat een mens laat zien. Het kent veel
overeenkomsten met het brein:
1] het bestaat uit losse units (processoren versus neuronen) en verbindingen tussen de units
2] ze kennen slechts 1 staat: vurend of niet (1 of 0 versus vuren of niet vuren)
3] ze kennen inhiberende en exciterende effecten op elkaar
4] ze werken beiden parallel
Met connectionische modellen zijn goede replicas gemaakt van hersenschade
waarbij de resultaten doen denken aan hoe ze bij ons voorkomen. Zo is anomia een
aandoening waarbij we een woord niet kunnen terughalen, maar waarbij priming nog
wel goed werkt.
HOOFDSTUK 8 : INTERACTIONS IN LONG-TERM MEMORY
Het onderzoek naar interacties tussen het semantisch en episodisch geheugen richt
zich op de invloed die zij op elkaar hebben bij het terughalen van herinneringen.
Hierbij wordt gebruik gemaakt van onderzoek waarbij men de (in)accuracy meet,
niet de reactietijd.
Schacter onderscheidt de seven sins of memory:
Transience : we vergeten informatie over de tijd
Absent-mindedness : vergeten van info komt meestal omdat we niet op letten tijdens
het encoden
Blocking : we kunnen de informatie niet terug halen, maar weten dat het er is (TOT-effect)
Misattribution : we herinneren iets correct maar attribueren het aan de verkeerde
bron
Suggestibility : de eigenschap informatie van anderen te verwerken in onze eigen kennis
Bias : al-aanwezige kennis vervormt de nieuwe kennis die we opdoen
Persistence : de eigenschap dingen te onthouden die we liever vergeten (trauma’s)
De eerste drie vallen in de groep ommission: net als het nodig is, zijn we het kwijt.
De volgende drie behoren tot commision: we herinneren iets, maar het is een foute
herinnering.
Ons geheugen is reconstructief. Bartlett toonde dat aan met een verhaal over
indianen dat herinnert moest worden. We onthouden de gist, de betekenis, niet een
exacte kopie (verbatim).
Reconstructie vindt plaats middels schemata; raamwerken van kennis over een
bepaald onderwerp waarin we nieuwe informatie proberen te weven. Past het niet?
Dan passsen we de informatie aan. De thematische effecten spelen een grote rol op
hoe we iets lezen/onthouden.
Bransford & Frank legden zinnen voor aan pp’s en voerden vervolgens een
recognitie-taak met de vraag of bepaalde zinnen gelezen waren. Hieruit bleek dat
geheugen is gebaseerd op de semantic integration van informatie; het is composiet
van aard (ongerelateerde informatie wordt, waar mogelijk, gekoppeld).
Er zijn twee typen accuracy die men kan meten:
Technical : de volledige, verbatim, kopie. Men met op woord-niveau
Content : de betekenis, de gist. Men meet of de betekenis (de kern) onthouden is.
Beiden zijn belangrijk. Technical accuracy bij zaken die we exact moeten onthouden.
Content accurary is belangrijk bij het doorgeven van informatie; de kern is relevant
(deze samenvatting). We hebben een integrative memory dat goed is in het laatste.
Nadeel is dat vervormingen kunnen optreden als het probeert ‘sense’ te maken van
nieuwe informatie en het vervormd.
>> PROPOSITIONS
Mensen herinneren de gist van een zin, niet de verbatim versie. Er wordt binnen de
cognitieve psychologie gebruik gemaakt van een methode om de gist van zinnen vast
te leggen in een schema (case grammar); de semantische rol van ieder woord wordt
bepaald. De ontlede zin is dan een proposition; een collectie van concepten die de
betekenis van een zin weergeven8.
Je hoeft op het tentamen geen zin te ontleden, maar je moet wel begrijpen hoe de methode werkt – de instructies
kun je het beste gewoon goed lezen en een paar keer oefenen.
8
Een zin wordt ontleed in semantisch delen en geschematiseerd:
Relation : de belangrijkste actie in de zin tussen de twee onderwerpen
Agent : de acteur, de uitvoerder van de actie
Patient / Recipient : de ontvanger van de actie
Location : de locatie waar de actie wordt uitgevoerd (indien aanwezig)
Time : De tijd waarin de zin geschreven is (past, present, enz).
De kracht van de methode is dat de propositie accuraat de beteknis van de zin
weergeeft, maar dat de verbatim versie sterk kan varieren (je kunt meerdere zinnen
verzinnen die de propositie goed uitdrukken). Dit lijkt dus op hoe ons geheugen
werkt.
Uit onderzoek blijkt dat proposities lijken te bestaan. Sachs was de eerste die dit
concludeerde (in zijn tijd was de case grammer er nog niet); mensen onthouden de
kern, niet de exacte versie. We zijn echter wel goed in het exact onthouden van
vreemde informatie : von restorff effect. We mogen priming verwachten. Woorden
in een zin hoeven strikt genomen niet semantisch gerelateerd te zijn, maar in de
context van de zin zijn ze wel gerelateerd. Priming treedt idd op.
Tijdens het comprehension (begrijpen) proces van een zin raadplegen we scripts die
gerelateerd zijn aan de situatie. Zij geven aan wat we mogen verwachten. Een zin als
‘het boek at de jongen op’ klopt dan ook niet met wat we volgens het script van een
boek mogen verwachten (een boek kan niet eten). Woorden als at, boek en jongen zijn
de headers; zij roepen scripts op. Woorden als waiter en hunger roepen samen
bijvoorbeeld het script op voor restaurant. De scripts bevatten slots of frames die de
gebeurtenissen aangeven die we mogen verwachten. Indien in de zin geen specifieke
informatie wordt gegeven omtrent zo’n gebeurtenis, dan vullen we die in met de
default value – dat wat we volgens het script mogen verwachten.
Er is veel bewijs voor scripts. Men legt dan een situatie voor waarbij essentiele
informatie weggelaten wordt en waarbij men kijkt of proefpersonen de gaten invullen
met eigen kennis. Recognitie bleek beter te zijn voor atypical events – zij strookten
niet met het script over een bepaalde gebeurtenis en bleven daarom beter hangen.
>> FALSE MEMORIES, EYEWITNESS MEMORY AND “FORGOTTEN MEMORIES”
Een false memory is een herinnering van iets dat niet gebeurd is. Men legt
bijvoorbeeld een lijst woorden voor die allemaal over slaap gaan, maar noemt het
woord slaap zelf niet. Vervolgens bepaald men hoeveel mensen het woord ‘slaap’ wel
denken te hebben gelezen.
Loftus liet pp’s een film zien van een botsing en vroeg hoe hard de auto’s elkaar
smashed / hit / bumped of collided. De groep met smashed gokte de hoogste snelheid
en dacht zelfs meer glasscherven te hebben gezien (terwijl die er niet waren). Een
leading question veranderde dus een eerdere herinnering; memory impairment; een
verandering in het geheugen als gevolg van een latere gebeurtenis.
Vaak legt men misinformation voor. Eerst krijgen pp’s een film te zien, vervolgens
krijgen ze misinformation (‘er stond een stop-bord’). Dat laatste word vervolgens
vaak geintegreerd in de herinnering van de film zelf; misinformation effect.
Er zijn drie redenen waarom geheugen niet volledig betrouwbaar is:
Source misattribution
We maken later geen onderscheid meer tussen de bron van informatie; onze eigen
herinnering of dat wat een ander ons vertelde?
Misinformation acceptance
We zijn geneigd misinformatie die goed past in de gebeurtenis gemakkelijk te accepteren.
Additionele informatie wordt onterecht aanvaard omdat het ‘logisch’ klinkt.
Overconfidence in memory
We zijn ons vaak erg zeker van een verkeerd herinnerd feit (‘ja, dat heb ik zelf gezien!’). Dit
kent twee redenen:
Source memory : het onderscheid tussen de bron van informatie verdwijnt; was het van onszelf, een ander?
Processing fluency : als we ons iets snel herinneren denken we dat het wel origineel moet zijn geweest
Zorgelijk zijn de methoden die door psychotherapeuten worden gebruikt. Vaak halen
zij zo valse herinneringen terug; zoals verkrachting, ontvoering door buitenaardse
wezens, enz.
>> AUTOBIOGRAPHICAL MEMORIES
Autobiographical memory is de studie van de herinneringen uit iemand’s eigen
leven. Bahrick onderzocht bijvoorbeeld hoe lang mensen de klasgenoten van de
middelbare herinnerden. Alhoewel de herinnering van de namen/gezichten slechter
werd, bleef de recognitie erg hoog. Dit komt door twee dingen:
Overlearning : we hebben de namen heel vaak gehoord en heel vaak gebruikt
Distributed learning : we hebben gedurende 4 jaar de naam geleerd
Men is er niet erg zeker van of autobiographical memory wel veel onderzoek
vereist. Het is misschien een stuk realistischer omdat het niet in een lab plaatsvindt,
maar in een lab kunnen veel factoren beter beperkt worden.
Het menselijk geheugen is misschien niet altijd in staat het juiste op het juiste moment
te herinneren, maar vaak:
1] vergeten we hoe vaak het wel goed gaat
2] vergeten we hoeveel informatie we eigenlijk ‘kennen’ – directe toegang is niet zo
makkelijk
3] we halen recall en remembering door elkaar. We heben vaak problemen met enkel de
recall
Troost je dus gelukkig. Over 15 jaar kun je 80% van wat in deze samenvatting staat
nog herkennen in een recognition test.
Flashbulb memories zijn speciale herinneringen die opgedaan worden bij belangrijke
gebeurtenissen (9/11 bijv). Deze herinneringen zijn veel gedetailleerder – mogelijk
door de spanning die we ervaarden.
HOOFDSTUK 9 : LANGUAGE
Taal komt overal voor. Het is een universeel onderdeel van het mens-zijn. De studie
van linguistics doet onderzoek naar taal. De eerste psychologen namen veel theorieen
over van deze academische tak toen het behaviorisme (mede door Chomsky – een
linguist) verworpen werd. Al snel bleek dat in de linguistiek, te weinig aandacht werd
besteed aan psychologische aspecten van taal. Dus ontstond een nieuwe tak;
psycholinguistics – de studie van taal zoals die gebruikt en geleerd wordt door
mensen.
Language is een gedeelde verzameling symbolen die bedoeld zijn voor
communicatie. Aspecten:
1] taal is symbolisch – klankenconstructies hebben een bepaalde betekenis
2] taal is shared – alle sprekers delen de betekenis van de symbolen met elkaar
3] taal maakt communication mogelijk
Hockett stelde 13 universele aspecten van taal op (linguistic universals):
Voice-auditory channel
Het kanaal voor alle taal-gebaseerde communicatie betreft vocaal-auditieve kanalen.
Schrift valt hier niet onder omdat een meer recente uitvoeding en niet elementair deel
van taal is.
Broadcast and directional reception
Linguistische transmissies worden in alle richtingen verspreid en kunnen door iedere (nabije)
toehoorder gehoord worden.
Transitoreiness: Rapid fading
Linguistische transmissies moeten op het juiste moment ontvangen worden; ze blijven niet
hangen en verdwijnen snel.
Interchangability
Menselijke taal bestaat uit eenheden die gebruikt kunnen worden voor productie en
comprehentie van gesproken taal. Alle sprekers kunnen beide taken uitvoeren.
Total feedback
We horen direct wat we zelf zeggen en kunnen het gezegde dus direct bijsturen.
Specialization
De klanken van een taal zijn bedoeld om een betekenis over te brengen. Niet-taal
gebaseerde communicatie zoals puffen of hijgen kan wel een betekenis hebben, maar
die wordt uit de context geinfereerd – en niet uit het puffen of hijgen zelf
(paralinguistic). Bij taal kan dit wel.
Semanticity
Taal brengt betekenis over.
Arbitrariness
De eenheden van taal geven geen hints over de betekenis van het woord. Het woord
‘bank’ verwijst op geen manier naar een 4-potig geval in je kamer. Hierom moet taal
een shared system zijn – iedere spreker/luisteraar moet dezelfde betekenissen
hanteren. Er zijn 2 consequenties:
Flexibility : omdat de relatie tussen woord/betekenis niet direct is, is taal heel flexibel en kan zo veranderd worden
Naming : we kunnen alles, zelfs abstracte zaken, nu een naam geven (en dat doen we dus ook).
Discreteness
Alhoewel klankpatronen een eindeloos aantal samenstellingen hebben, worden er
maar een aantal gebruikt binnen een taal.
Displacement
Taal stelt ons in staat om over meer te praten dan slechts het heden. Door gebruik van
past/present/enz-tense kunnen we praten over het verleden, heden en de toekomst.
Productivity
Het construeren van taal gebeurt bij iedere zin. Het is geen systeem dat simpelweg
geleerde zinnen herhaald – het construeert iedere zin actief en vormt steeds nieuwe
zinnen die toch hetzelfde betekenen. Mogelijkheden zijn feitelijk eindeloos.
Duality of patterning (duality of structure)
De mogelijke klanken kunnen eindeloos gecombineerd worden. Niet de geluiden zelf
hebben een betekenis, maar de combinatie bevat de betekenis.
Cultural and traditional transmission
Taal wordt aangeleerd door blootstelling. iit dieren – bij hen ligt communicatie
genetisch vast
Vergeleken met dieren is onze taal heel flexibel. De taal van chimpansees is slechts
arbitrair in dat ze klanken kennen voor bepaalde roofdieren. Maar ze zijn echter
beperkt in:
Displacement : ze kunnen slechts over het heden communiceren
Productivity : ze kunnen geen zinnen construeren van de klanken die ze kennen
Naming : ze kennen geen namen voor anderen belangrijke objecten als eten, bomen, enz
Flexibility : ze kunnen de klanken voor dieren niet veranderen (taal is niet echt
shared).
Er zijn vijf niveaus waarop analyse van taal uitgevoerd moet worden:
1] phonology : analyse van de klanken van een taal – hoe zij uitgesproken en begrepen
worden
2] syntax : analyse van de woordvolgorde en de regels van grammatica die daarbij
komen kijken
3] lexical or semantic : analyse van woordbetekenis en integratie van betekenis in zinnen
4] conceptual : analyse van zinbetekenis met semantische kennis al aanwezig bij
spreker/hoorder
5] belief : analyse van zinbetekenis mbt overtuigingen en motivaties van de spreker
Traditioneel linguistisch onderzoek richt zich enkel op de grammar; de regels die
gelden voor hoe zinnen opgebouwd mogen worden. Dit heeft betrekking op de eerste
drie niveaus. De laatste twee aspecten zijn typisch onderdeel van de psycholinguistic.
Onderzoek naar taalgebruik kan men doen op twee manieren:
Competence : de geinternaliseerde kennis van taal en de regels die ervoor gelden
Performance : de geuitte taal. Het eigenlijk taalgedrag.
Chomsky vindt de eerste het belangrijkste. De prestatie van taal is tenslotte het
gevolg van een groot aantal mentale processen (zoals geheugen) waarin eenvoudig
fouten op kunnen treden waardoor we ‘uhm’ zeggen, even stoppen, opnieuw
beginnen, enz (dysfluencies). Chomsky vertrouwt liever op de linguistic intuitions –
wat wil de spreker eigenlijk – wat hij precies zegt is minder belangrijk. De door hem
gebruikte methode is dan ook het laten keuren of een zin wel of geen goede zin is.
Psycholinguisten, echter, zijn juist geinteresseerd in de performance omdat men
daarmee wat kan zeggen over de mentale processen.
Whorf’s hypothesis stelt dat taal mentale processen, onze manier van denken, direct
beinvloedt. Taal vormt de manier waarop je over de wereld denkt. Ook wel de
linguistic relativity hypothesis genoemd. De sterkste versie zegt dat je niet kunt
denken over dingen die geen naam hebben in je taal. De zwakkere versie zegt dat dat
wel kan, maar veel moeilijker is.
>> PHONOLOGY : THE SOUNDS OF LANGUAGE
Phonology vormt het regelsysteem dat bepaalt hoe klanken gecombineerd mogen
worden in een taal. Het is het meest elementaire aspect van taal.
Phonemes zijn de elementaire bouwstenen van een taal. Het zijn ieder categorieen
voor een aantal klanken die gezien worden als hetzelfde, ook al zijn er fysieke
verschillen (bijvoorbeeld de ‘k’ uit ‘cool’ en ‘kat’). Hier zijn twee belangrijke
aspecten van belang:
Alle klanken in dezelfde categorie worden als hetzelfde verstaan (categorical perception).
Verschillende phonemen zijn die klanken die verschillend klinken
Alhoewel met de phonemen oneindig veel woorden geconstrueerd kunnen worden,
zijn er slechts een aantal geldig. Middels regels, de phonemic competence, die we
onbewust toepassen weten we welke combinaties wel en niet mogen (‘spnk’ is geen
nederlands woord, ‘sponk’ zou dat wel kunnen zijn).
Hoe werkt het verstaan van gesproken tekst? Ontleden we de woorden in klanken om
de betekenis te ontwaren? Nee, want dat staat gesproken taal niet echt toe vanwege
deze zaken:
Problem of invariance
De klanken waarmee we spreken varieren van spreker tot spreker, van keer tot keer dat we
spreken. Bovendien beinvloeden eerdere klanken in een woord verdere klanken of andersom.
Meerdere klanken worden tegelijkertijd gearticuleerd – niet stuk voor stuk (coarticulation).
Word seperation and pauses
In tegenstelling tot wat we verwachten zijn de pauzes tussen woorden vaak korter dan
pauzes in woorden zelf. De scheiding tussen woorden is dus niet zo duidelijk.
Om taal te begrijpen moeten we de context meten. Taalbegrip is grotendeels
conceptually driven. Dit is aangetoond in een experiment waarbij onzin-zinnen en
echte zinnen gepresenteerd werden. Proefpersonen hadden veel meer moeite met het
nazeggen van de onzin-zinnen dan de echte zinnen.
>> SYNTAX: THE ORDERING OF WORDS AND PHRASES
De syntax geeft aan hoe woorden als elementen van een zin geplaatst mogen worden
in relatie tot elkaar. De studie van syntax richt zich op de vraag hoe woordvolgorden
tot betekenisvolle zinnen leiden. Het probeert de regels (grammar) die hiervoor
gelden te beschrijven.
De betekenis van een zin wordt beinvloedt door:
word order ‘ik vroeg de man de weg’ versus ‘de man ik vroeg weg de’
phrase order ‘ze vroeg me maandag weg te gaan’ versus ‘maandag vroeg ze me
weg te gaan
Chomsky heeft een theorie opgesteld om de syntactische structuur te beschrijven:
Phrase structure rls lexicon & lexicon insertion rls deep structures transformation component surface
structure
semntic compnent semantic
representations
Phrase grammer is volgens Chomsky van belang voor het vormen van de zin, de
volgorde en groepering van woorden en de relatie tussen woorden en subzinnen.
Zinnen die hierdoor gegenereerd worden, worden aangevuld door het lexicon en
regels die aangeven welke woorden hoe ingevoegd moeten worden. Hieruit volgt een
deep structure; een abstracte representatie van de zin. Deze ‘zin’ is van groot belang
om twee redenen:
1] de deep structure wordt door transformationele component tot een goede zin omgevormd.
2] de deep structure wordt door een semantisch component omgezet in een betekenis
Zinnen kunnen ambigue zijn omdat ze één surface structure en meerdere semantich
representations hebben. Dit wordt duidelijk als we de zin actief ontleden (parsing).
De surface structure kan ook varieren terwijl de semantic representation gelijk blijft
(‘the boy kissed the girl’, ‘the girl was kissed by the boys’).
Psychologisch gezien is syntax van belang om de comprehentie bij de ander zo
eenvoudig makkelijk te laten zijn. Dit werd door linguisten echter niet onderzocht
daar zij geen waarde hechtten aan performance. Bock legde enkele belangrijke
psycholinguistische zaken voor:
Automatic processing
In hoeverre is de productie van taal automatisch of bewust?
Planning
Uit onderzoek blijkt dat we al beginnen te spreken terwijl het einde van de zin nog
niet geplanned is. Dit gaat in tegen Chomsky’s strikt hierarchische model. Hoe werkt
deze planning?
>> LEXICAL AND SEMANTIC FACTORS: THE MEANING IN LANGUAGE
Het laatste niveau in het linguistische onderzoek richt zich op de betekenis in taal.
Een groot onderdeel hiervan is het ophalen van woordbetekenissen uit het mentale
lexicon. Woorden en betekenis hangen nauw samen, zoals blijkt uit priming
experimenten. Bovendien moet bepaalt worden hoe woorden in een zin zich tot elkaar
relateren wil men de betekenis begrijpen (‘Jill saw Bill’ versus ‘Bill saw Jill’).
De kleinste betekenis-volle unit in een taal is een morpheme. ‘Cars’ bestaat uit twee
morphemes: ‘car’ en ‘-s’ (een betekenisvolle toevoeging). Onduidelijk is nog of we
een woord als ‘cars’ geheel opslaan, of dat onze hersenen de meervoud-vorm
berekenen op basis van ‘Car’ en ‘-s’.
Bij het begrijpen van een zin is de lexicale representatie van groot belang. We meten
meer van woorden dan enkel hun betekenis. Een zin als ‘het boek zat achter het kind’
aan kan niet, omdat we weten dat een boek niet uit zichzelf kan bewegen. Deze fouten
worden duidelijk als we een semantische analyse uitvoeren waarbij de semantische rol
van ieder woord bepaald wordt (case grammar). Een syntactische analyse zou de
betekenis missen.
Semantische en syntactische elementen werken samen en beinvloeden elkaar. Als
iemand ons iets vraagt, dan weten we (semantisch) dat we een vraag moeten
beantwoorden en passen de syntax van het antwoord aan zodat het een antwoord
wordt. Maar de semantiek kan ook de syntax overstijgen. Dit bleek in onderzoeken
waarin personen foute zinnen moesten overschrijven. Vaak verbeterden ze de zin
onbewust. Ze begrepen wat bedoeld werd.
Uit deze semantische grammar benadering volgen twee voorspellingen:
1] we beginnen een zin te begrijpen zodra we woorden beginnen te horen
2] dit doen we door ieder woord een semantische rol binnen de zin toe te kennen
Dit is te merken bij zinnen als ‘nadat de muzikant had gespeeld op de piano werd deze
snel van het podium gehaald’. Hier moet je halverwege opnieuw beginnen omdat de
zin anders loopt. Dit noemen ze ook wel garden path sentences waarbij het
gemakkelijke eerste v/d zin je op het verkeerde been zet.
De case grammar heeft de basis gevormd voor de propositie-theorieen uit het
vorige hoofdstuk.
>> BRAIN AND LANGUAGE
Aphasia is een storing in taalgebruik door een hersen-gerelateerd probleem door
ziekte of beschadiging. Er zijn een aantal vormen:
Broca’s aphasia
Door een beschadiging in Broca’s area is de patient niet meer in staat goede spraak te
produceren. Spraka is langzaam en vaak phonemisch verkeerd. Ze begrijpen
geschreven en gesproken taal echter nog wel.
Wernicke’s aphasia
Het tegenovergestelde gebeurt bij beschadiging van het deel van Wernica. Taalbegrip
is gehinderd net als lezen, herhalen en benoemen. Maar syntactisch gezien zijn de
patienten goed in staat zinnen te vormen – alleen kloppen de woorden niet.
Conduction aphasia
Patienten kunnen niet herhalen wat net gezegd is. Dit komt door schade aan de
arcuate fasciculus: de verbinding tussen wernicke’s en broca’s delen.
Anomia
Patienten kunnen objecten niet meer benoemen.
Van deze aandoeningen kan men generaliseren dat syntax en semantiek plaatsvinden
in andere delen van de hersenen. Bovendien is het brein biologisch aangelegd om
talen te leren.
Dankzij nieuwe imaging technieken kunnen onderzoekers een beter beeld krijgen van
het brein en hoe zij omgaat met taal. Bij het leren van een onzintaal bleken na een
tijdje dezelfde reacties op te treden als bij een gewone taal.
HOOFDSTUK 10 : COMPREHENSION: WRITTEN AND SPOKEN LANGUAGE
Hoe begrijpen wij wat we lezen. Hoe werkt comprehension? Dit heeft alles te
maken met de twee hoogste niveaus van Miller (eerder beschreven): beliefs en
conceptual knowledge.
Als we lezen, maken we ook gebruik van onze conceptual knowledge. Een zin als ‘ik
zag de berg vliegen’ klopt volledig – het mentale lexicon staat de zin toe, maar hij
kan niet omdat we weten dat bergen niet vliegen. Ook al vertel ik jou dat bergen
kunnen vliegen, dan nog weet je dat het niet kan en dat ik hoogstens zelf iets anders
geloof. Een puur linguistische analyse mist al dit.
Comprehension vindt ook plaats door:
Referencing : het begrijpen dat twee woorden in één zin naar hetzelfde verwijzen
Pragmatics : het begrijpen van hoe een zin opgevat moet worden. ‘Heb je tijd?’ = niet
letterlijk
Conversational interactions : regels die aangeven hoe gesprekspartners de reacties
structureren
Deze regels passen we automatisch toe. Ze zijn impliciet.
Traditioneel onderzoek werd uitgevoerd door Sachs en Javella. Sachs liet
proefpersonen zinnen zien, en vroeg ze na een bepaalde interval de zin ter herkennen
uit een aantal (vergelijkbare, maar niet volledig gelijke) zinnen. Hij ontdekte dat
mensen direct na het lezen van de stimulus, de juiste zin pikten, maar dat, na een
pauze, men slechts zinnen kon verwerpen die een andere betekenis hadden. Hij toonde
aan dat de gist vastgelegd wordt, niet de verbatim versie. Javella toonde aan dat de
zin uit het geheugen wordt gewist (slechts de gist blijft achter), als de zin begrepen is.
Deze studies beantwoorden echter minder vragen dan ze voortbrachten. Er was vraag
naar meer precieze methoden. Die werden gevonden in online comprehension
experiments waarbij de tijd direct gemeten wordt terwijl de taak plaatsvindt. Men
meet de tijd, terwijl de taak complexer gemaakt wordt. Het verschil geeft aan hoeveel
‘complexer’ mentale processen zijn. Dit kan met:
Written language
Men presenteert een zin, gevolgd door een woord. De proefpersoon moet aangeven of
het woord in zin voorkwam. Een woord dat makkelijker te begrijpen moet sneller
herkend worden.
Spoken language
Men krijgt een zin te horen, en moet een knop indrukken bij het horen van een
bepaalde phoneme. Men verwacht dat dit sneller gaat bij simpelere delen van een zin.
Volgens Gernsbacher onderscheidt het volgende stappenmodel voor
comprehension:
1] we beginnen met het bouwen van een mentale structuur zodra we beginnen met de zin
2] we mappen verdere informatie die de zin biedt in die structuur
3] we beginnen met een nieuwe structuur zodra een zin dat vereist.
De eerste woorden uit een zin hebben een advantage of first mention – ze blijven
langer beschikbaar in het geheugen. De laatste woorden hebben ook een voordeel;
advantage of clause recency, maar zij verdwijnen uiteindelijk sneller uit het
geheugen dan de eerste woorden. Het eerste woord is tenslotte centraal voor de door
ons gebouwde mentale structuur. Het woord ‘the’ als eerste woord lijkt positieve
effecten te hebben op het verdere begrip van de zin.
Tevens onderscheidt Gernsbacher twee mechanismen die bij comprehension
werken:
Enhancement
Woorden die gerelateerd zijn aan de zin worden geactiveerd in het semantische
netwerk en zijn gemakkelijker toegankelijk (priming).
Suppression
Woorden die niet gerelateerd zijn aan de zin worden onderdrukt en minder gemakkelijk
toegankelijk voor verdere processen. Tijdens het lezen van de zin worden steeds meer
begrippen onderdrukt, omdat ze niet meer in de scope van de zin vallen.
Maar hoe begrijpen we zinnen die samen een verhaal vormen? Hoe weten we dat de
zinnen aan elkaar relateren? Volgens sommige onderzoekers geldt het situational
model hier – we stellen ons de situatie letterlijk voor. Dit is door onderzoek
bevestigd.
>> REFERENCE, INFERENCE AND MEMORY
Twee belangrijke language devices zijn nodig bij het begrijpen van zinnen:
Reference
Referentie is het proces waarbij verwezen wordt naar een (eerder) genoemd concept
met een andere naam (‘De auto is weg. Hij was rood’). De antecedent is hierbij het
concept (‘auto’) en de anaphoric reference de terugverwijzing (hij).
Implication and inference
Implicatie is niet zo voor de hand liggend. Het is het maken van een referentie naar
iets dat niet expliciet genoemd wordt in de zin zelf (‘het tentamen wordt moeilijk’
impliceert ‘goed leren!’).
Inferentie is het proces waarbij de lezer of de luisteraar probeert conclusies te trekken
uit het gezegde.
Simpele referenties komen heel veel voor. Het zou raar zijn als we alles in een zin
zouden moeten expliciteren (‘Christiaan schrijft deze samenvatting. Christiaan
verkoopt zijn samenvatting. Christiaan wordt stinkend rijk’ is anders dan ‘Christiaan
schrijft deze samenvattingen, verkoopt ze en wordt stinkend rijk’).
Clark heeft een aantal soorten referentie en implicatie onderscheiden:
Direct reference
Identity : Christiaan koopt een computer. De computer is te koop.
Synonym : Christiaan koopt een computer. De machine is te koop.
Pronoun : Christiaan koopt een computer. Hij was te koop
Set membership : Ik sprak met Christiaan vandaag, hij vertelde me dat hij een cmp.
heeft gekocht
Epithet : Christiaan koopt een computer. Het stomme ding werkt echter niet.
Indirect reference by association
Necessary parts : Christiaan koopt een computer. De processor is echter kapot.
Propable parts : Christiaan koopt een computer. Het toetsenbord is echter kapot
Inducible parts : Christiaan koopt een computer. De prijs was laag.
Indirect references by characterization
Necessay roles : Ik kocht gisteren een computer. Het kostte me 500 euro.
Optional roles : Ik kocht gisteren een computer. Mijn bankrekening is nu leeg.
Other
Reasons : Christiaan koopt een computer. Hij hoopt indruk te maken met het ding (nou…..)
Causes : Christiaan koopt een computer. Hij heeft het nodig voor school.
Consequences : Christiaan koopt een computer. Zijn vrienden zijn onder de indruk
(nou…..)
Concurrences : Christiaan koopt een computer. Peter koopt ook een computer.
De meeste zinnen vereisen mentale processen die een brug slaan tussen de zinnen en
de woorden. Dit wordt door Clark bridging genoemd; het leggen van een connectie
tussen concepten. De spreker en de luisteraar kunnen elkaar echter verkeerd begrijpen
omdat:
Unauthorized implication : een verkeerde implicatie in de opmerking gemaakt door de
spreker
Unauthorized inference : een verkeerde opvatting van de opmerking door de
luisteraar.
Indien alles wel goed gaat, is er sprake van een authorized inference.
Inferenties gedurende comprehension zijn soms vrij eenvoudig, maar soms erg
moeilijk en indirect. Er zijn meerdere stappen die plaatsvinden gedurende het proces:
1] we halen gerelateerde begrippen uit het geheugen, en maken gebruik van ‘cues’ uit de zin.
2] de informatie moet in het werkgeheugen terecht komen zodat het gebruikt kan
worden.
3] de betekenissen van de begrippen worden geintegreerd in één begrip van de zin.
De meningen zijn echter verdeeld over in hoeverre we gerelateerde begrippen ophalen
en koppelen (brigden – inferenties maken). Halen we alle mogelijk gerelateerde
zaken op? Of alleen die informatie die nodig is om de zin coherent te maken
(minimalistic approach). Huidige onderzoeken doen vermoeden dat lezers inderdaad
heel ver gaan met het maken van inferenties
Individuele verschillen laten zien dat ervaren lezers beter in staat zijn niet-relevante
zaken in teksten te onderdrukken (supression) terwijl ze een grotere enhancement
kennen die bovendien langer aanwezig blijft.
>> READING
Lang had men moeite met het onderzoeken van lezen. Tegenwoordig meet men hoe
lang mensen naar woorden in een zin kijken: gaze duration procedures. Dit vereist
echter aannamen:
Immediacy assumption
Lezers proberen een woord dat ze lezen direct te begrijpen. Het is niet zo dat we eerst een
groep lezen en die daarna proberen te begrijpen.
Eye-mind assumption
Het oog blijft gefixeerd op het woord waar mentale processen mee bezig zijn. Dit is lang een
controversiele aanname geweest, maar is nu geaccepteerd.
Deze onderzoeken lieten een aantal dingen zien:
1] we kijken heel kort, of zelfs helemaal niet, naar vulwoorden als the, of, and, enz
2] we kijken lang naar de eerste woorden van een zin of woorden die we niet kennen
Tijdens het lezen kijken we vaak terug naar eerder gelezen woorden middels saccades
v/d ogen. Er wordt vaak een onderscheid gemaakt tussen first pass duration (tijd dat
men keek naar het woord toen men het voor het eerst zag) en total pass duration
(totale tijd – dus inclusief eventuele terugblikken).
Just en Carpenter hebben een model opgezet voor reading. Naast het
microscopische bewijs, dat per woord aangeeft hoelang mentale processen duren,
proberen zij ook conclusies te trekken over macroscopische zaken – het bevatten van
grotere stukken tekst. Zij onderscheiden een long-term memory dat allerlei kennis
bevat, een short-term memory waar de actieve comprehentie plaatsvindt en en een
aantal processen die tijdens het lezen plaatsvinden9. Op basis hiervan bepaalden zij
wat de effecten van soorten processen (nieuw woord, naar nieuwe zin, enz) zouden
hebben op de lengte van de gaze duration.
9
Zie blz 426 voor dit model. Ik zou hem niet uit mijn hoofd gaan leren
Zowel top-down als bottom-up processen spelen een grote rol, maar geen van hen is
dominant. Comprehentie wordt sterk beinvloedt door linguistische effecten in de tekst.
Top-down processen ‘vlakken’ oppervlakkige fouten vaak zo uit dat we ze niet eens
meer zien of zorgen ervoor dat we juist problemen ervaren (met zogenaamde garden
path zinnen).
>> SPOKEN LANGUAGE AND CONVERSATION
Ook speech comprehension is moeilijk te onderzoeken. Tegenwoordig gebruikt men
een vergelijkbaar systeem als bij het lezen. Men geeft pp’s een knop en laat ze
woorden of zinsdelen horen. Zodra ze begrijpen wat ze horen, drukken ze op de knop
om een volgend deel te horen. Men meet vervolgens de reactiesnelheid. De resultaten
laten zien dat comprehension bij reading en listening hetzelfde gaat.
Conversaties kennen een eigen structuur:
Taking turns
Gesprekken gebeuren altijd in beurten. De spreker zegt iets, de luisteraar beantwoordt
op stelt zelf een vraag. Men gebruikt een heleboel (verbale en niet-verbale signalen)
om aan te geven dat óf de spreker klaar is met zijn zin, óf dat de luisteraar iets wil
zeggen.
Social roles and setting
Sociale rolen spelen een grote rol. Een superieur mag bijvoorbeeld eerder inbreken in
iets wat gezegd wordt.
Conversaties kennen ook een aantal cognitieve factoren:
Conversational rules
Er worden vier regels onderscheiden die van belang zijn bij gesprekken:
1] relevance: zeg alleen dat wat relevant is voor het gesprek
2] quantity: zeg niet meer dan strikt nodig is
3] quality: zeg wat waar is
4] manner and tone: wees helder
Topic Maintenance
Bovendien moeten we zorgen dat onze contributes zinvol en relevant zijn.
Online theories during conversation
We construeren een beeld van de persoon met wie we spreken (direct theory) en een
beeld van wat deze persoon van ons denkt (second-order theory). Op basis daarvan
maken we beslissingen over gemaakte opmerkingen en passen eventueel ons niveau
van spreken aan aan het niveau van de toehoorder.
Er is veel onderzoek gedaan naar indirect requests. Daarbij vraagt men verkapt iets
wat men wil (‘het is hier koud’ sluit het raam). Uit onderzoek blijkt dat men bij
simpele indirect requests waar enkel ‘ja’ zou volstaan, men toch meer als antwoord
geeft.
Bovendien blijkt dat we in eerste instantie altijd uitgaan van onze eigen perspectieven
en pas daarna gebruik maken van het perspectief van de ander (egocentric speech).
HOOFDSTUK 11 : DECISIONS, JUDGEMENT AND REASONING
Er zijn twee typen formal logic die van belang zijn:
Syllogisms
Twee premises waaruit een conclusie komt die altijd waar of altijd niet waar is. De
premises zijn bijvoorbeeld ‘alle katten zijn dieren. Alle dieren zijn wild’. Hieruit volgt
dat alle katten wild zijn. Logisch gezien klopt deze uitspraak, maar de premises zelf
zijn echter niet valide (niet alle dieren zijn wild).
Conditional reasoning
Een vorm van redeneren waarbij gekeken wordt of het aanwezige bewijs een
conclusie mogelijk maakt. Een zin als “ik ben nieuwe student, dus ik moet me
inschrijven” is een voorbeeld. De voorwaarde over de student vormt de antecedent.
De voorwaarde van het inschrijven is de consequent. Uit de antecedent volgt de
consequent. IF-THEN. We kunnen:
- de antecedent bevestigen: ik ben een nieuwe student ik moet inschrijven (modus
ponens)
- de antecedent ontkennen: ik ben geen nieuwe student geen conclusie
- de consequent bevestigen: ik schrijf me niet in ik ben geen nieuwe student
(modus tollens)
- de consequent ontkennen: ik moet me inschrijven geen conclusie
Er zijn dus twee valide argumenten. Hier komen geldige (correcte) conclusies uit
voort. De andere argumenten zijn niet-valide – er komt geen conclusie uit voort. Over
het algemeen zijn mensen goed in het werken met de modus ponens (het bevestigen
van de antecedent en het trekken van een conclusie). De modus tollens wordt door
veel mensen echter niet begrepen.
Fouten in het conditionele denken komen voort uit een aantal fouten:
Form errors
Men gebruikt het ontkennen van de antecedent en trekt daaruit een (onmogelijke) conclusie.
Vaak zijn fouten meer subtiel – men draait de IF-THEN proposities vaak onbewust om en
trekt daaruit ongeldige conclusies: “ik schrijf me in dus ik ben een nieuwe student”.
Vervolgens ben ik, volgens deze uitspraak inderdaad een nieuwe student als ik me moet
inschrijven – maar volgens de oorspronkelijke uitspraak mogen we dat niet zomaar
concluderen.
Search errors
Mensen zoeken vaak naar positief bewijs voor een stelling, terwijl ze veel beter
kunnen zoeken naar negatief bewijs. Dit is de confirmation bias. Als ik zeg ‘als ik
turk ben, ben ik crimineel’. Veel mensen zoeken alleen bevestiging, en niet
ontkrachting. De Wason card trick is hier een voorbeeld van. Er liggen 4 kaarten met
op iedere kaart een nummer aan de voorkant en een letter aan de andere kant. De regel
die geldt is “als een kaart een klinker als letter heeft, heeft het een even cijfer aan de
andere kant”. In plaats van te zoeken naar bevestiging, kun je beter zoeken naar een
kaart waarvoor dat niet geldt.
Memory-related errors
Volgens Johnson-Laird lossen we logische problemen op door mentale modellen te
construeren. Hoe ingewikkelder de uitspraak, hoe meer mentale modellen nodig zijn
en hoe zwaarder de last op het werkgeheugen wordt.
De hierboven beschreven benadering geldt ook voor de wetenschap. In plaats van te
zoeken naar bewijs voor een hypothese, kan men de hypothese beter omdraaien in een
null-hypothese en daar bewijs voor zoeken. Als ik de zwaartekracht wil bewijzen,
moet mijn null-hypothese zijn dat een appel niet valt als ik hem loslaat. Die nullhypothese kan ik verwerpen door het te testen.
>> DECISIONS
Hoe maken we beslissingen? Volgens Collins en Loftus gebruiken we het netwerkmodel waarbij geactiveerde nodes bewijs voor of tegen de vraag vormen. Bij ‘is een
vleermuis een vogel?’ zijn er een aantal nodes die bewijs bieden voor de stelling
terwijl anderen er tegen pleiten.
De studie van de psychophysics doet onderzoek naar hoe perceptuele verschillen van
de fysieke stimulus waargenomen worden. Hierbij is de just-noticible difference een
belangrijk begrip – het minimale verschil tussen twee stimuli dat we nog kunnen
waarnemen. Het benodigde verschil wordt steeds groter als de intensiteit van de
stimulus toeneemt. Hetzelfde verschil tussen twee zeer felle lampen zal moeilijker te
zien zijn dan bij twee minder felle lampen. Hoe groter het verschil tussen 2 stimuli,
hoe makkelijker ze te onderscheiden zijn: discriminability effect.
Bovenstaand onderzoek is concreet. Tegenwoordig gebruikt men symbolic
comparisons waarbij geen fysieke stimuli, maar symbolische stimuli worden
gebruikt. Men tekent bijvoorbeeld twee balonnetjes waarbij de ene iets hoger dan de
andere hangt. Hierbij duurt het voor mensen langer als ze moeten beantwoorden
welke lager hangt. Dit is het semantic congruity effect. De dimensie hoger ligt meer
voor de hand bij een ballon en wordt daarom sneller beoordeel. Bij symbolic
comparisons treden ook symbolic distance effects op – het is gemakkelijker te
zeggen welke hoger hangt als de balonnen verder uit elkaar liggen.
Deze effecten gelden ook voor nummers. Het is makkelijker te bepalen welke
nummer de grootste is bij grote nummers, dan bij twee kleine nummers. Hoe groter de
afstand tussen twee nummers, hoe gemakkelijker dit echter gaat. Dit gaat echter
steeds moeilijker. De afstand tussen 1 en 2 is gevoelsmatig kleiner dan tussen 8 en 9
of tussen 10000 en 10001. Nummers liggen niet op een lineaire schaal, maar kennen
een logaritmische schaal.
Dit is ook gevonden bij het bepalen van afstanden tussen twee geografische locaties.
De afstand tussen Utrecht en Amsterdam lijkt groter dan de afstand tussen New York
en Boston. Toch is dat niet zo. We geloven ook dat Chicago hoger ligt dan Rome. Dat
is niet zo. Kortom; de logaritmische schaal wordt vrijwel overal gevonden.
>> DECISIONS AND REASONING UNDER UNCERTAINTY
We nemen beslissingen op basis van:
Algorithms : Volledige uitgeschreven procedures die altijd een goed resultaat geven
(wiskunde)
Heuristics : meer gok-werk dat geen strakke richtlijnen kent en foute antwoorden kan
geven
Kahneman en Tversky hebben veel onderzoek gedaan naar heuristics. Zij
onderscheidden:
Representativeness Heuristic
Een regel die stelt dat de kans op het optreden van een gebeurtenis beinvloedt wordt
door hoe gelijk die gebeurtenis is aan de populatie waar hij uit voortkomt of in
hoeverre de uitkomst overeen komt met het proces dat het produceerde
Availability Heuristic
Schattingen worden beinvloedt door het gemak waarmee relevante voorbeelden naar
voren gehaald kunnen worden.
Simulation Heuristic
We maken een voorspelling van de toekomst, op basis van een andere set omstandigheden
dan de omstandigheden die nu zijn opgetreden (wat als de nazi’s eerder een a-bom zouden
hebben?)
De representativeness heuristic kent een aantal sub-biases:
Insensitivity to sample size bias
We houden zelden rekening met de grootte van de groep waaruit iets komt. Hoe kleiner de
groep, hoe groter de kans op uitschieters (normale verdeling). Toch houden we daar geen
rekening mee
Stereotype bias
Onze verwachtingen worden vaak gekleurd door stereotypen. Deze verwachtingen
worden daardoor vervormd – niet beter gemaakt (‘steelt een turk meer?’)
De representativeness bias levert dus soms foute conclusies op. Dat is natuurlijk niet
altijd zo, en hij kent dus wel degelijk een nut. Stereotypen hebben wel degelijk enige
basis.
De availability bias kent een aantal sub-biases:
Familiarity bias
We zien gebeurtenissen als belangrijker of meer voorkomend als we bekender met ze zijn in
het geheugen.
Salience and vividness bias
Vliegtuigen zijn veel veiliger dan autos. Toch denken de meesten van niet. Dit komt
omdat de paar vliegtuigrampen die voorkomen veel ernstiger lijken en meer
dramatisch overkomen. Ze zijn meer vivid en blijven daarom langer hangen
(bovendien komen ze meer in het nieuws).
De kennis die we gebruiken bij deze bias is general world knowledge. In de VS is de
verkoop van trucks op autos 1:1. Dat zou je niet verwachten omdat je dagelijks meer auto’s
ziet.
De simulation heuristic kent een aantal sub-biases en heuristics:
Undoing heuristic
Treedt soms op bij counterfactual reasoning, het veranderen van de gebeurtenissen om
een bepaalde ‘what if’ situatie te bereiken. Wat als de nazi’s eerder de a-bom hadden gehad?
Dit vereist het veranderen van eerdere gebeurtenissen. We kunnen aantal veranderingen
maken:
Downhill changes : we laten gebeurtenissen weg die belangrijk waren voor de huidige uitkomst (‘hij vertrok niet
vroeger’)
Uphill changes : we voegen gebeurtenissen toe die de verwachte situaties mogelijk maken (‘hij kreeg een lekke
band’)
Horizontal changes : een detail wordt vervangen door een detail met dezelfde kans op optreden (‘hij reed
langzamer’)
Hindsight Bias
Het beoordelen van het optreden van een gebeurtenis na het inderdaad optreden van die
gebeurtenis. Meestal zeggen we dan ‘zie je wel! Ik had het verwacht’. Dit komt omdat die
gebeurtenis nu beter in het geheugen ligt, en andere zaken waar we aan dachten minder te
herinneren zijn.
We gebruiken veel vaker downhill changes daar zij eenvoudiger zijn. Horizontal changes
worden eigenlijk nooit gebruikt. Een voorbeeld-onderzoek is het vertellen van een verhaal
waarbij een bestuurder verongelukt. Men kan een ‘what if’ situatie maken door te vragen wat
er zou kunnen zijn gebeurd om de botsing te vermijden. Voorbeelden van antwoorden staan
in de tabel. We blijken ons bovendien te richten op het onderwerp van het verhaal. De
bestuurder zelf, en niet zozeer de andere betrokken auto bij het ongeluk.
>> LIMITATIONS IN REASONING
In veel gevallen is ons denken gewoon te beperkt om een probleem middels een
algoritme op te lossen. Onze domain knowledge is dan limited. We gebruiken bij het
oplossen mentale modellen. Zij hoeven niet perse volledig te kloppen met de realiteit.
Dit geldt vooral bij gebieden zoals natuurkunde, statistiek, scheikunde, enzovoorts.
McCloskey kwam met de term naïve physics om aan te geven hoe ‘leken’
natuurkundige problemen (verkeerd) oplossen. Wat gebeurt er als je een bal
rondslingert aan een touw en het touw loslaat? De bal zal in een rechte baan
wegvliegen. Velen geloven dat de bal echter nog steeds enige kromming in zijn baan
zal kennen.
Het toepassen van algorithms kost vaak veel working memory resources en tijd.
Daarom gebruiken we heuristics – ook al is de betrouwbaarheid dan minder. Uit
onderzoek blijkt inderdaad dat mensen met een beschadiging aan de frontal lobes
meer problemen ervaren met moeilijker problemen. Het werkgeheugen bevindt zich
dus daar.
HOOFDSTUK 12 : PROBLEM SOLVING
Problem solving wordt onderzocht middels verbal protocols. Men vraagt personen
hoe zij problemen oplossen. Alhoewel er kritiek is omdat het lijkt op introspectie, is
er geen andere manier. Deze tak van de cognitieve psychology heeft, vanwege zijn
moeizaamheid, lang geen aandacht gehad.
De gestalt psychologen begonnen met het onderzoek naar probleemoplossing. Zij
zagen mentale processen niet als ontleedbaar. De som is meer dan de delen. Kohler
deed onderzoek bij apen. Hij liet ze proberen een banaan te krijgen die net te hoog
was. Hij ontdekte dat er een moment was waarop de aap ineens de oplossing wist:
insight of het ahah-moment. Een plotse oplossing.
Het oplossen van problemen is vaak moeilijk door een:
Functional fixedness
We zijn geneigd oobjecten te gebruiken op de manier waar ze voor bedoeld zijn.
Soms moet een object, bij het oplossen van een probleem, juist heel anders gebruikt
worden.
Negative set
We zijn geneigd problemen op te lossen volgens manieren die eerder werkten. We blijven
een specifieke, eerder-werkende, methode vaan gebruiken zelfs als er betere methoden zijn.
>> INSIGHT AND ANALOGY
Insight is een diep, volledig begrip van de aard van iets – voornamelijk een probleem. Soms
komt dit via een analogie – een vergelijkbare situatie die we al wel opgelost hebben.
Metcalfe en Wiebe onderzochten insight-momenten. Zij ontdekten twee dingen:
1] mensen zijn accuraat in het schatten van de benodigde tijd voor bekende problemen
2] oplossingen komen zeer plots
Toch zijn veel wetenschappers niet overtuigd dat de oplossing werkelijk zomaar komt. Het
kan ook zijn dat de negative set of functional fixedness ineens verdwijnt. Misschien is insight
slechts het vinden van een kritieke benodigde inferentie. Voor kinderen lijkt iig te gelden dat
insight eerst op een onbewust niveau komt – ze weten niet hoe ze het probleem opgelost
hebben. Bij het nogmaal maken blijkt dat ze het dan wel weten – dan is de oplossing bewust
geworden.
Analogieen bieden goede methoden om problemen op te lossen. De multiconstraint theory
voorspelt hoe mensen analogieen gebruiken bij het oplossen van problemen en welke
factoren een rol spelen bij de te gebruiken analogieen. Onderscheidden factoren:
Problem similarity
De problemen moeten enigszins overeen komen. De source domain moet lijken op de target
domain.
Problem structure
Er moet een parallel gevonden worden tussen de structuren van beide problemen, zodat
elementen van het niet opgeloste-probleem gemapped kunnen worden op die van het al
bekende probleem.
Analogy purpose
De doelen in beide problemen moeten overeen komen. Alhoewel problemen qua structuur
veel op elkaar kunnen lijken, kan het zo zijn dat we ze toch niet als analogie gebruiken omdat
de doelen anders zijn (zie het verschil tussen de ‘radiation’ en ‘attack dispersion’ en ‘parade
problem
Recentelijk neurologisch onderzoek heeft laten zien dat de linker frontal en parietal lobes
actief zijn bij analogy problems. Bij insight problems lijkt de right hemisphere een grote rol
te spelen.
>> BASICS OF PROBLEM SOLVING
De gestalt mistte een wetenschappelijke wijze van onderzoek. Huidig
reductionistisch onderzoek probeert de delen wel te onderzoeken. Het oplossen van
een probleem heeft altijd een goal; het verwachte eindpunt of de oplossing. Het kent
verder de volgende eigenschappen:
Goal directedness
Het oplossen van een probleem wordt geuit door goal-directed behavior.
Sequence of operations
Probleem-oplossing verloopt in kleine sequentiele stappen waarin men steeds dichter bij de
oplossing komt.
Cognitive operations
Er wordt gebruik gemaakt van verschillende cognitieve operaties. Men denkt, schrijft, leest,
praat, enzovoorts.
Subgoal decomposition
Het oplossen van problemen betekent het opsplitsen van het probleem in subgoals.
Een probleem met geen subgoals is eigenlijk ook geen probleem.
De problem space is van belang bij probleem-oplossing. Het bestaat uit de initiele,
tussen en uiteindelijke doelen van het probleem. Het bevat ook de aanwezige kennis
van de persoon bij iedere stap. Er ontstaat een hierarchische oplossingsboom die de
stappen en de subgoals beschrijft. Het oplossen van een probleem is metaforisch
gelijk aan het afzoeken van een boom met oplossingen. Aanwezige informatie in het
probleem zelf, kan de zoektocht kleiner maken (prunen).
De problem space kent een aantal elementen:
Operators
De operators zijn de toegestane operaties om een probleem op te lossen. Soms
beperkt het probleem de mogelijke operaties.
Goal
Dit is het uiteindelijke doel van het probleem. Sommige doelen zijn well-defined als
ze duidelijk aangeven wat de beginnende en uiteindelijke states moeten zijn. Ze zijn
ill-defined als dat niet duidelijk is (de meeste dagelijkse problemen zijn ill-defined).
>> MEANS-END ANALYSIS: A FUNDAMENTAL HEURISTIC
Means-end analysis is de bekendste heuristiek om problemen op te lossen. Het is het
oplossen van een probleem in stappen door, per stap, steeds te bepalen wat het
verschil tussen de huidige en de gezochte staat is. Vervolgens zoekt men een
procedure of handeling om dat verschil kleiner te maken. Het kent dan ook 5 stappen:
1] definieer doel of subdoel
2] kijk naar het verschil tussen het doel en de huidige staat
3] zoek naar operator om dat verschil te verkleinen (of zet een nieuw subdoel op)
4] pas de operator toe
5] herhaal stap 2-4 totdat alle subdoelen en het uiteindelijke doel bereikt is.
De tower of hanoi is een goed voorbeeld van deze manier van oplossen – zie blz 521.
De gemakkelijkste versie kent 3 disks en 3 pegs. Moeilijkere versies hebben bijv 4
disks. Een 4-disk tower kent eigenlijk 2x 3-disk tower problemen.
Op basis van bovenstaande procedure is de GPS – general problem solver –
ontwikkeld. Dit is een computerprogramma dat problemen op kan lossen. Het vormde
bovendien de basis voor latere connectionistische modellen. Het GPS formuleerde een
production system model. Een production is een IF-THEN statement. IF ‘regent’
THEN ‘jas aantrekken’. Het GPS werkte goed, behalve bij problemen waarbij je
feitelijk een stap terug moet doen om dichterbij te komen. Het model van de GPS kan
dat niet – het probeert het verschil tussen staat en doel steeds te verkleinen, en kan het
niet vergroten (ook al is dat tijdelijk).
Een nieuw systeem is de ACT* (Act-star) wat staat voor adaptive control of thought.
Het kent:
Declarative memory
Dit bevat wereldkennis (zowel episodisch als semantisch).
Production memory
Dit bevat alle IF-THEN statements. Het is procedural knowledge die aangeeft wat
gedaan moet worden in welke situatie. Feitelijk een hele waslijst met IF-THEN
statements
Working memory
Dit is het werkgeheugen, de werkbank en de plek waar de huidige staat vastgehouden wordt.
Na iedere procedure wordt het werkgeheugen gescanned en wordt de huidige staat
vergeleken met alle IF-THEN statements. Als er een statement gevonden wordt dat
van toepassing is bij de huidige staat, dan wordt deze uitgevoerd.
>> IMPROVING YOUR PROBLEM SOLVING
(we zijn d’r bijna – bijna aan het einde van het boek – nog even doorbijten)
Je eigen vermogen tot het oplossen van problemen kan verbeterd worden door:
Increase your domain knowledge : laat je kennis over het domein van een probleem
groeien
Automate some components of problem-solving : ontlast werkgeheugen door veel
oefening
Follow a systematic plan : stel een systematisch plan op op papier, en volg dat
Draw inferences : voorspel uitkomsten en verlaat ze als ze niet zullen gaan werken
Develop subgoals : stel subdoelen op en werk die eerst uit
Work backward : Veel wiskundige problemen kun je beter andersom oplossen: goal
initial state
Search for contradictions : zoek naar contradicties (kras op tentamens foute
MCantwoorden weg)
Search for relations among problems : probeer een vergelijkbaar (bekend)
probleem te vinden
Find a different problem representation : probeer naar een analogie te zoeken
Practice : oefening baart kunst. Je kunt geen problemen oplossen als je het nooit
oefent.
HET BREIN TE KIJK : HOOFDSTUK 4 – WAARNEMEN
Het vermogen tot zien is zonder meer één van de belangrijkste vermogens die we
hebben. Huidig cognitief onderzoek is vooral gericht op de waar-vraag en (nog) niet
zozeer op de hoe-vraag. In vroeger tijden werd de waar-vraag vooral beantwoordt
dmv dieren en mensen met hersenschade.
Munk deed in de 19e eeuw veel onderzoek naar waarneming en concludeerde dat de
occipital lobe belangrijk is voor visuele informatieverwerking, en in het bijzonder de
striate cortex van dit deel. Dit gebied wordt ook wel de primaire visuele cortex of
gebied V1 genoemd.
Hubel en Wiesel slaagden er in te bepalen welke cortexcellen belangrijk waren bij het
waarnemen van bepaalde soorten bewegingen. Zij boden lijnpatronen aan die
bewogen en bepaalden welk deel van de hersenen actief werd. Bepaalde gebieden
bleken specifiek te reageren op lijnpatronen met een bepaalde hoek. Neurale
substraten kennen dus een eigen taak.
De lokalisatie van gebieden gebeurde veel bij apen. Het probleem is echter dat de
locatie van gebieden wel eens blijkt te varieren tussen mens en aap.
>> VISUELE VERWERKING IN HET KORT
Licht van op het retina, het netvlies. Dit netvlies bestaat uit kegeltjes, die
geconcentreerd zijn in de fovea, en staafjes die daarbuiten meer geconcentreerd zijn.
De kegeltjes zijn voor kleur-visie en de staafjes voor zwart/wit. De staafjes zijn
gevoeliger voor licht. Na de retina worden signalen via de oogzenuw naar de
hersenen gestuurd. De oogzenuw van ieder oog splits zich in het optisch chiasma.
Het linker visuele veld wordt gerepresenteerd door de rechter hemisfeer en andersom.
In iedere helft bevindt zich het ontvangststation voor de oogzenuw; de corpus
geniculatum laterale (GCL). Deze kern heeft een retinoptische structuur, dat wil
zeggen die in het retina bij elkaar liggen, hier ook bij elkaar liggen. Tevens is de kern
verdeeld in een zestal lagen waarvan de bovenste vier parvocellulaire lagen worden
genoemd en de onderste twee magnocellulaire lagen. Deze verdeling ontstaat in de
retina waar twee typen ganglion-cellen voorkomen: parasol en midget cellen. De
axonen van de parasol cellen vormen de magno lagen terwijl de axonen van de
midget cellen de parvo lagen vormen. Informatie verlaat de GCL via vezels die
uitwaaieren (radiatio optica) en komt netjes retinoop aan bij het V1-gebied.
In het V1-gebied ontstaat een scheiding tussen what en where. De what-informatie
wordt door de temporale kwab afgehandeld (onderkant) en de where wordt door de
parietale kwab afgehandeld (bovenkant).
Alhoewel er sprake is van paden in het brein, is er sprake van heel veel communicatie
tussen deze paden – ze zijn dus niet strikt gescheiden. Er is zowel bottom-up als topdown beinvloeding daar latere processen beinvloedt worden door eerdere processen
en andersom.
>> ONDERZOEK BIJ HERSENGEBIEDEN
Nieuwe methoden als fMRI en PET zorgen voor nieuwe mogelijkheden. Men biedt
stimuli aan en meet vervolgens wat er in het brein gebeurt. Hierbij is de volgende
verdeling mogelijk:
Bepaling van grenzen
Men probeert de grenzen tussen hersengebieden te bepalen. Men gebruikt hier fMRIscans
Bepaling van functie
Men probeert de functie van hersengebieden te bepalen. Welk deel wordt actief bij
welk type stimulus? Men gebruikt hier PET-scans.
De bepaling van grenzen is goed mogelijk bij vroegere gebieden. Hier zijn de delen
nog sterk retinotopisch van aard. Deze topografische organisatie maakt het mogelijk
om te bepalen dat het visuele gebied uit vier kwadranten bestaat. Een beschadiging
van een specifiek deel van de hersenen leidt het inactief worden van het kwadrant
rechts-boven, bijvoorbeeld. Men kan een helft laten wegvallen (hemianoop) of een
kwart (kwadrantaopsie). De retinotopische aard blijft tot redelijk diep in het brein
bewaard.
De bepaling van de grenzen zegt nog niets over de functie. Er lijkt bijvoorbeeld een
deel van het brein te zijn dat reageert op gezichten: fusiform face area (FFA).
>> ZIEN VAN BEWEGING
De waarneming van beweging is de meest belangrijke. Vroeger dacht men dat
beweging iets was dat zich buiten de persoon bevondt en dat de hersenen slechts
inferereerden dat beweging plaatsvond omdat object X zich op moment 1 elders
bevond dan op moment 2. Nu weet men dat het niet zo simpel is. Het watervalexperiment, en de Phi phenomenon geven aan dat beweging waargenomen wordt
door de hersenen en ook waargenomen kan worden als het feitelijk niet bestaat.
Het brein kan verschillende soorten snelheden waarnemen. Dit kan alleen als het
signaal van beide detectoren (zintuigen) op hetzelfde moment in het brein aankomt.
Dit vereist dus dat er een vertraging is tussen het deel van het zintuig (rechteroog) dat
het waarneemt en het deel (linkeroog) dat het zintuig dat de latere positie
waarneemt10.
Gebied V1 is belangrijk bij het waarnemen van lokale beweging. Een lokale beweging is een
beweging in een object dat zelf ook beweegt. Bijvoorbeeld de zwarte stippen op de huid van
eenr rennend luipaart. Maar hoe kan het dat ons brein weet dat de brei stippen behoort tot
één object? Het groeperen vindt plaats in V1 en V5 (ookwel MT). Voor complexe
bewegingen lijkt een gebied na V5, het MST-gebied, van belang te zijn. Ook gebied V3A lijkt
van belang voor beweging. Dit in tegenstelling tot gebied V3 zelf – die dat niet is (dit is
andersom bij apen).
Beweging naeffecten geven een goed middel om beweging te onderzoeken. Het watervalexperiment is een voorbeeld pp’s krijgen een waterval te zien die plots stopt met stromen.
Toch ervaart de pp nog steeds een beweging – deze gaat echter juist omhoog. Er is geen
eenheid over waar dit zich bevindt, maar het lijkt erop dat V5 hier belangrijk is.
De verdeling van het visuele deel van het brein is ongeveer als volgt:
V1 : bewegingen lokale beweging
V3A : bewegingen gevoelig – exacte functie niet beschreven
V4 : kleur er bestaat op dit moment echter een discussie of dit wel echt zo is.
V5 : bewegingen groepering
V8 : kleur het nieuwe ‘kleur’ gebied dat onderkent is ter vervanging van V4.
MST : beweging complexe beweging
10
Dit is een wazig stuk dat volgens mij heel niet klopt – lees bladzijde 82 eens, het voorbeeld is wel duidelijk.
>> ATTENTIE EN WAARNEMING
Met attentie kun je waarneming sturen. Het is mogelijk omgeving te verkennen
zonder daadwerkelijk je ogen te bewegen. Dit blijkt bijvoorbeeld uit een
richtingsambigue plaatje, zoals een kruis dat draait, maar niet in een specifieke
richting. Door je aandacht te richten kun je het kruis andersom laten draaien. Wat er
in de hersenen gebeurd is nog onduidelijk. Conclusie is dat een hoger proces als
aandacht de waarneming kan beinvloeden.
>> GEZICHTSHERKENNING EN DE WAT- EN WAAR-ROUTES
Men begon te vermoeden dat er een waar- en wat-route bestond toen bleek dat
beschadigingen in verschillende gebieden tot andere problemen leidde:
Temporaalkwab : moeite met closure-taken (herkenning) wat associatieve
seelenblindheit
Occipitaalkwab : moeite met doolhof-taken (locatie) waar apperceptieve
seelenblindheit
De term seelenblindheit is tegenwoordig vervangen door agnosia. Er is sprake van
een dubbele dissociatie. Schade in het ene pad leidt niet tot disfunctie van de ander en
andersom.
Gezichtsherkenning vindt plaats in een speciaal gebied. Er is een gebied waar de
cellen gaan vuren bij het zien van een bekend gezicht. Schade leidt tot prosopagnosie
– het onvermogen gezichten te herkennen. Delen van de fusiform gyrus worden
actief bij gezichtsherkenning. In dit deel v/h brein bevinden zich delen die elementaire
primaire vormen coderen. Het deel dat zich bezighoud met gezichtsherkenning
bevindt zich daar ook tussen. Men noemt dit de fusiform face area. Een ander
gebied, de parahippocampal place area reageert op andere objecten. De amygdala
reageert op de mate van ‘triestheid’ van het gezicht.
>> CONCLUSIE
Het is moeilijk conclusies te trekken uit onderzoek bij dieren. Ook bij PET en fMRI
blijkt het nog moeilijk te zijn tot dezelfde conclusies te komen. De vele gebruikte
manieren, de vele onderzoeksmethoden en statistische methoden maken het toch
moeilijker dan men zou verwachten.
HOOFDSTUK 6 : HET GEHEUGEN, VERANDERINGEN IN HET BREIN
[ veel van dit hoofdstuk staat al in Ashcraft, ik heb alleen nieuwe informatie
opgenomen ]
Geheugen is de eigenschap die door evolutie verzonnen is om de evolutie te
comprimeren binnen de levensloop. Het stelt ons in staat binnen de levensloop te
veranderen. Geheugen werkt door middel van associaties die letterlijk bestaan uit
koppelingen die zich vormen tussen neuronen. Leren is het veranderen van een
reactie door het herhaaldelijk optreden van een prikkel. Leren leidt tot veranderingen
in verbindingen tussen neuronen. Die veranderingen samen vormen het geheugen.
Hebb stelt dat de verbinding tussen neuronen sterker wordt als hij vaker gebruikt
wordt. In eerste instantie is deze verbetering tijdelijk. Pas na een tijd, na de
consolidatie, wordt de verbinding permanent. Cells that fire together, wire together.
Hoe kan men leren?
Temporary learning
Tijdelijk leren treedt op als neuronen binnen korte tijd vaak geactiveerd worden. De
verbinding wordt sterker gedurende weken of jaren. Dit heet long-term potentiation
en het treedt vooral op in de hippocampus. De gevoeligheid van de neuronen neemt
tijdelijk toe door enzymen die de eiwitsynthese beinvloeden.
Permanent learning
Permanente veranderingen treden op door messenger-proteinen die synapsen en
zenuwen direct veranderen. De synapsen worden groter, de oppervlakte neemt toe en
de ion-kanalen nemen toe in aantal.
Glutamate en GABA zijn betrokken bij exciterende en inhiberende effecten op neuronen.
Neurotransmitters bevorderen of remmen het leren van nieuwe informatie. Transmitters die
vrijkomen bij emotionele reacties, als adrenaline, dopamine, endorfinen, acetylcholine en
serotonine, versterken of onderdrukken de overdracht van signalen bij synapsen.
Experimenten hebben ratten geproduceerd die beter leren doordat zij meer glutamaatreceptoren hebben.
Het brein kent een hoge plasticiteit; het kan eenvoudig veranderen, maar moet dat wel doen
in bepaalde kritische fasen. Het leren van taal gaat bijvoorbeeld binnen een bepaalde
periode. Neuronen die niet gebruikt worden sterven af.
>> LOCATIE VAN HET GEHEUGEN
Lashley zocht naar het engram – de neurale representatie van een herinnering. Hij
concludeerde dat het engram niet op één plek ligt, maar verspreid is over het gehele
geheugen. Hij trok deze conclusie na onderzoek met ratten in een doolhof waarbij hij
vervolgens laesies aanbracht in de hoop de herinnering van het pad te verbreken. Dat
lukte niet. Kritiek is echter dat de herinnering helemaal niet zo simpel was, en bestond
uit vele herinneringen door vele zintuigen. Kleine laesies verstoorden slechts delen
terwijl grote laesies meer verstoorden.
Er is een lokalisatie mogelijk van bepaalde hersendelen. Bij ophalen/opslaan van
herinneringen:
Linker prefrontale cortex : het vormen van nieuwe herinneringen
Rechter prefrontale cortex : het ophalen en bewust worden van bestaande
herinneringen
Het brein bestaat uit een groot aantal deelsystemen die gespecialiseerd zijn in
bepaalde taken. Bij iedere taak is een groot aantal van deze systemen betrokken. Het
geheugen is niet op één plek te lokaliseren.
Semantisch geheugen ontstaat uit het episodisch geheugen. We doen ervaringen op,
en vormen kennis uit die ervaring. Semantisch geheugen hebben we echter wel nodig
om ‘sense’ te maken uit episodisch geheugen. Toch zijn het aparte delen, zoals blijkt
uit beschadigingen:
Amnesie : deze mensen hebben problemen het episodische herinneringen
Afasie : deze mensen hebben problemen met semantische herinnering (herkennen,
benoemen)
Bij amnesie is de bibliotheek van episodische herinneringen zelf niet beschadigd,
maar de drukpers om die informatie erin te krijgen, de hippocampus, is dat wel.
De door Baddeley onderscheiden delen van het geheugen zijn verspreid over het
brein. Shimamura stelt dat de prefrontale cortex belangrijk is bij het filteren van
relevante van onrelevante informatie. Zij spelen een grote rol in het werkgeheugen.
Koppelingen van de prefrontale cortex met de visuele cortex en andere delen, maakt
het mogelijk voor de prefrontale cortex andere hersendelen actief te houden.
Er bestaan grofweg twee soorten geheugen:
Impliciet : geheugen waar we ons niet bewust van zijn
Expliciet : geheugen waar we ons wel bewust van zijn
Bij amnesie werkt het expliciete geheugen niet goed, maar het impliciete geheugen
vaak wel. Er bestaan dus twee aparte systemen voor. Beiden kennen een speciale
vorm van leren:
Impliciet activatieleren : het treedt automatisch op bij het activeren van bestaande
associaties
Expliciet elaboratieleren : treedt op bij het opslaan van episodische herinneringen
Geheugenfuncties en de meest betrokken neurale kernen:
Declaratief geheugen (expliciet herinneren)
Werkgeheugen:
Episodisch:
Semantisch:
prefrontale cortex
hippocampus en de mediale temporale cortex
gespecialiseerde gebieden in de neocortex
Nondeclaratief geheugen (impliciet herinneren)
Repetition priming:
de neocortex
Vaardigheden en gewoonten: basale ganglia (striatum)
Conditioneren:
basale ganglia (amygdala) en cerrebellum
>> NEURAAL MODEL VAN HET BREIN
Bij iedere waarneming worden representaties gevormd of geactiveerd. Zij ontstaan
door ervaring – de interactie tussen synapsen van neuronen. Representaties zijn
netwerkjes van verbonden neuronen. Semantische herinneringen vormen zich uit
episodische herinneringen omdat constante elementen steeds samen geactiveerd
worden (je ervaart steeds hetzelfde). Episodische herinneringen bestaan echter uit
koppelingen tussen semantische representaties die voorkwamen in de gebeurtenis.
De episodische herinneringen worden gevormd door de hippocampus. Hij heeft
verbinden met veel delen van het brein, en koppelt representaties in het brein aan
elkaar (en vormt zo dus episodische herinneringen). Toch is deze rol maar tijdelijk.
Mensen met amnesie vergeten vaak enkel recentelijke episodische herinnengen.
Schijnbaar verdwijnen langdurige episodische herinneringen naar een ander deel van
het brein. Dit behoort tot het trace-link model.
>> NEURALE BASIS VAN VERGETEN EN HERINNEREN
Herinneren is het activeren van bestaande neurale verbindingen. Hierbij zijn cues van
belang waarbij de ene neuron geprikkeld wordt, en de ander mee geprikkeld wordt
(prime). Psychologen nemen aan dat enkel de juiste cues uiteindelijk verdwijnen, en
niet dat herinneringen zelf verdwijnen.
HOOFDSTUK 7 : TAAL EN HET BREIN
[ veel van dit hoofdstuk staat al in Ashcraft, ik heb alleen nieuwe informatie
opgenomen ]
Ons mentale lexicon bestaat uit ongeveer 50.000 woorden waarvan we er 2 tot 4 per
seconde kunnen toepassen in spraak en begrip. Men probeert een begrip te krijgen van
de processen door een mentaal model te bouwen van de mentale processen die
betrokken zijn bij spraak.
In de negentiende eeuw begon lokalisatie van functies met de frenologie. Men
dacht dat veel-gebruikte, goed ontwikkelde, gebieden in het brein ook groter moesten
zijn en uitstulpingen veroorzaakten in de schedel. Alhoewel deze gedachte nu niet
meer geldt, zaten ze er niet erg ver af als het om taal gaat. Broca, Wernicke en
Lichtheim ontdekten functionele gebieden:
Broca’s area : Van belang bij vorming fonetische constructies.
Wernicke’s area : Van belang bij taalbegrip. Het bevat woordbeelden – betekenis
van woorden
Fasciculus arcuatus : de verbinding tussen wernicke’s en broca’s gebied
Na deze periode, de lokationalistische periode, werd het idee verworpen dat
hersengebieden specifieke taken kende. De holisten zagen het brein als één geheel. In de
cognitieve revolutie ging men weer terug naar het eerdere, lokalistische, onderzoek.
>> WOORDEN IN HET BREIN
Woorden kennen twee doorslaggevende eigenschappen voor classificatie en ordening:
Grammatica
Alle woorden behoren tot een grammaticale klasse. Sommige woorden zijn
inhoudloos (functiewoorden) en bestaan enkel om inhoudswoorden te koppelen. Uit
onderzoek blijkt dat het brein onderscheid maakt tussen deze soorten woorden;
inhoudswoorden worden langer verwerkt.
Semantiek
Op semantisch niveau vertonen woorden hun betekenis. Veel woorden zijn ambigue;
ze betekenen iets in één context, maar iets anders in een andere context.
Sommige mensen hebben problemen met het gebruik van zeer specifieke klassen. Zij
kunnen dieren, planten of eten niet categoriseren. Dit komt door schade aan de
primitieve amandalkernen in het brein.
Middels cross modal priming doet men onderzoek naar ambigue woorden. Zo blijkt
dat alle betekenissen van een woord kort actief worden. De betekenissen die niet in de
context passen worden echter snel weer gedeactiveerd.
Soorten afasie:
Amnestische afasie
Patienten hebben een constant tip-of-the-tongue probleem met inhoudswoorden. Zij
gebruiken veel empty speech (enkel functiewoorden daar die makkelijk in gebruik
zijn). De woorden zijn nog wel in het lexicon, maar ze kunnen niet goed opgehaald
worden. Feitelijk hebben alle afasiepatienten hier in meer of mindere mate last van.
Wernicke’s afasie
Ook het begrijpen van gesproken taal is nu aangetast. Men hoeft niet echt lang te
zoeken naar een woord, maar gebruikt vaak de verkeerde woorden in de verkeerde
context; parafasieen. Zij zijn zich niet bewust van de eigen gemaakte fouten.
Conductie afasie
Woordbeelden (Wernicke’s area) en klankbeelden (Broca’s area) zijn in orde, maar
communicatie is verstoord (fasciculus arcuatus). Men maakt fonematische
parafasieen waarbij klanken verkeerd uitgedrukt worden. Men is zich bewust van de
eigen fouten en verbeterd zichzelf dus steeds.
>> WOORDEN IN HET BREIN
Men heeft bij het meten van hersenpotentialen gebruik gemaakt ERPs. Deze methode
maakt het bepalen van de functie van een gebied echter zeer moeilijk. Ook de bron is
niet goed te bepalen. Met PET en fMRI is dit een heel stuk beter mogelijk.
De omzetting van een gedachte in een woord gebeurt in vier stappen:
conceptuele verwerking
De betekenis van woorden. Het middelste deel van de mideelste temporaalgyrus in de
linkerhelft is hierbij betrokken. Concepten vormen hier de representaties.
grammaticale verwerking
De grammaticale verwerking van woorden vindt plaats in Wernicke’s gebied. De achterzijde
van de middelste en de bovenste temporaalgyrus in de linkerhersenhelft zijn hierbij
betrokken. Woordvormen, of lemma’s, vormen hier de representaties
fonologische verwerking
De fonologische verwerking vindt plaats in Broca’s gebied. Hier wordt de klankvorm omgezet
in fonologische code. Woordklanken, of lexemen, vormen hier de representaties.
articulatorische verwerking
Dit articulatie van woorden wordt gecoördineerd door de supplementaire motorschors.
Motorprogramma’s vormen hier de representaties.
Het begrijpen van taal begint met een omzetting van de spraak in een prelexicale
fonologische code. Deze code wordt vervolgens een selectie uitgevoerd om de
woordvormen te bepalen. Lemma-activatie en conceptuele analyse komen overeen
met die die bij spraak gelden.
>> ZINSVERWERKING IN HET BREIN
Er vinden twee debatten plaats over de aard en de werking van het taalsysteem.
Aard : syntax en semantiek gescheiden?
Zijn de synactische en de semantische delen gescheiden systemen? De
connectionisten stellen van niet.
Werking : in hoeverre zijn syntactische en semantische verwerking losstaand?
Vindt eerst een syntactische verwerking plaats, en dan pas de semantische
verwerking? De modulisten stellen van niet en de interactionisten stellen van wel.
De antwoord op het eerste debat wordt geleverd door onderzoek met ERPs. Men meet hoe
het brein reageert op een zin met een semantische fout en/of een zin met een grammaticale
fout. Hieruit blijkt dat de potentialen bij beiden anders zijn (de ene is negatief, de ander
positief). Men neemt aan dat andere neuronengroepen andere potentialen veroorzaken.
Hiermee is dus aangetoond dat beide soorten verwerking plaatsvinden in andere
hersendelen.
Onderzoek met ambigue zinnen kan antwoorden voor het tweede debat leveren. In
een ambigue-zin is sprake van een zin waarbij de syntax gelijk is en blijft, maar
waarbij twee semantische betekenissen ontleend kunnen worden. Men presenteert een
ambigue zin en meet de ERP. Hieruit blijkt dat de semantische informatie direct
invloed heeft op de syntax-verwerking. De interactieve theorieen worden dus
ondersteund.
>> NEUROANATOMISCHE BASIS VAN GRAMMATICALE ZINSVERWERKING
Er is nog weinig onderzoek gedaan naar de hersenactiviteit bij verwerking van
gehele zinnen. Vroeg onderzoek laat zien dat de frontale opperculum actief wordt
bij kennis en verwerkingsprocessen die nodig zijn om grammaticaal correcte uittingen
te produceren.
COLLEGE 1 : AANDACHT (KENEMANS)
Aandacht is een verzameling processen dat waarmee het brein het doen en laten
reguleert. Er zijn twee soorten aandacht:
Input/stimulus-aandacht : aandacht bij het luisteren (of opvangen van informatie)
Output/response-aandacht : aandacht bij het handelen
Verschillende vormen van aandacht vinden hun bron in andere delen van het brein.
De anterieurse cingulate nucleus richt globale aandacht
De thalamus richt specifieke aandacht op een specifiek deel
De parietal lobe richt het aandachtskader
ADHD is een aandoening waarbij een verstooring in de aandacht optreedt. De criteria
(DSM) zijn:
A : Inattentie of hyperactivititeit-impulsiviteit
De patient moet tenminste aan 6 vormen van inattentie (gebrek aan aandacht) hebben
‘geleden’ gedurende tenminste 6 maanden óf De patient moet tenminste 6 maanden
vormen van impulsiviteit of hyperactiviteit hebben ervaren.
B : Symptoms occuring before age 7
Een deel van bovenstaande symptomen moet al voor het zevende levensjaar
opgetreden zijn.
C : Symptomen in meerdere locaties
De symptomen worden geuit in tenminste twee of meer locaties
(thuis/werk/school/enz)
E : Ernstige stoornis
Er moet sprake zijn van een duidelijke ernstige klinische stoornis in sociaal, academisch, of
occupationele handelen.
Er zijn twee typen van ADHD:
1] aandachtstekortstoornis : gecombineerd type
2] aandachtstekortstoornis : overwegend onoplettend type
Patienten ervaren in alle gevallen meer interferentie bij een Stroop-taak. Aandachtstekort
gaat soms samen met een afgenomen arrousal.
Maar hoe ontstaat de aandoening? Mogelijk is er sprake van een te lage arrousal-ratio. Dat
beteknent dat iemand dus niet reageert op een stimulus. De hyperactiviteit wordt mogelijk
verklaard door een te hoge arrousal omdat de tonische arrousal (spontane communicatie
tussen neuronen bij rust) te hoog is.
Men kan arrousal meten middels een EEG. Men meet dan verschillende voltages; beta,
alpha, theta, delta enz. Snelle golven duiden dan op een hoge arrousal, terwijl langzame
golven op een lage arrousal duiden. Om de arrousal in het algemeen vast te stellen berekent
men de theta/beta ratio. Deze is hoger bij een aandachtstekort.
Men kan ADHD bestrijden middels methylphenidate. Dit werkt het beste bij mensen met een
lage arrousal (hoge theta/beta ratio). Het verhoogt de arrousal (vreemd genoeg).
COLLEGE ? : PSYCHONOMIE VS PSYCHOLOGIE
Dit is een hele verhandeling over het Eurake-project van Frans Verstraten. Ik was niet in staat
hier ook maar iets interessants uit te halen dat ze ook kunnen vragen. Daarom vertel ik zelf
maar een verhaal dat feitelijk op hetzelfde neerkomt (toevallig mijn eigen interesse – een
stukje wetenschapsfilosofie)
Het komt erop neer dat psychonomen het brein ontleden in stukjes en die delen onderzoeken
in de hoop het geheel, de mens, te begrijpen. Er is veel kritiek op die methode. Het wordt ook
wel ‘de moderne frenologie’ genoemd. Dit is bovendien een fundamenteel probleem met de
psychologie als geheel. Men kan de delen wel ontleden en begrijpen, maar begrijp je dan ook
wel het geheel? De reductionistische methode die de wetenschap kenmerkt gaat ervan uit dat
dat zo is. Dit is echter een niet te bewijzen aanname. Wetenschap ontleedt een theorie in
steeds kleinere theorieen die men probeert te bewijzen om uiteindelijk alles weer samen te
brengen. Je kunt de som begrijpen door de delen te begrijpen. De gestalt-psychologen
kwamen hier al eerder op terug en stelden dat de som veel meer is dan slechts de delen
opgeteld.
De vraag is of je de mens, en vooral de geest, dus mag ontleden in stukjes. Binnen de
psychologie bestaan begrippen, zoals ‘bewustzijn’, die niet gereduceerd kunnen worden in
kleinere problemen. Of neem iets als een ervaring als pijn. Je kunt ‘pijn’ niet reduceren tot iets
kleiners. Je kunt pijn niet verklaren volgens de reductionistische methode. Lijkt raar, niet?
Stel dat ik jou prik, dat doet pijn, niet? Waarom doet het pijn? Je verklaart pijn niet door te
komen met een heel biologische verhaal van zenuwbanen, pijngebieden in het brein,
enzovoorts. Waar in het brein wordt dan besloten dat ‘pijn’ een inherent vervelend gevoel
voor jou is? Feit is dat ‘pijn’ iets is dat niet onderzocht kan worden. Met alle
wetenschappelijke middelen die bestaan kun jij niet bepalen *hoe* pijn voelt. Je hebt een
bewust persoon nodig die jou uitlegt hoe pijn voelt (en dan nog komt hij niet verder dan
‘vervelend’ en ‘au!’). Met alle wetenschappelijke apparatuur kun jij niet uitleggen wat het is om
verliefd te zijn. Je kunt natuurlijk hormomen en neurotransmitters aantreffen die horen bij het
‘verliefde gevoel’, maar je kunt niets zeggen over de inhoud van het gevoel. Je kunt niet
bepalen wat een persoon moet voelen die verliefd is. Dat kun je alleen als je een persoon bij
de hand hebt die je dat uit kan leggen.
Dit verhaal gaat nog wel een tijdje door, maar Verstraten eindigt met de conclusie dat we het
gewoon niet weten. “Bewustzijn” is iets dat niet echt wetenschappelijk te onderzoeken is. Je
kunt alle delen van het brein kennen en begrijpen, maar dan nog begrijp je niet waarom een
persoon bewust is en hoe dat zo komt. Bewustzijn is meer dan de delen van de som, en je
kunt het niet begrijpen door de delen te begrijpen. Bewustzijn is niet te reduceren en daarom
niet wetenschappelijk te onderzoeken.
COLLEGE ? : PROBLEEMOPLOSSING
Een probleem bestaat uit:
1] een startsituatie (al dan niet in je hoofd)
2] toegestane operatoren en middelen
3] eventuele beperkingen die je mogelijkheden inperken
4] een doel dat je wilt bereiken
Een probleem bestaat uit een boom met stappen. Bij iedere stap maak je een keuze, die leidt
tot een andere tak. Je kunt de boom blind doorlopen (zonder intelligentie – een algoritme) of
dmv een heuristiek. De volgende blinde methoden bestaan:
Breadth-first : eerst alle breedte-stappen waarbij je steeds een niveau lager gaat
Depth-first : je doorloopt ieder mogelijk pad vanaf het begin tot het einde (brute force)
De volgende heuristische methoden bestaan:
Hill-climbing
Bij iedere keuze wordt het beste alternatief gekozen. Je kunt dan echter vastlopen in de boom
omdat je niet terug kunt gaan in de boom en uiteindelijk, zelfs na de ‘beste’ alternatieven toch
een verkeerd einde hebt (dit lijkt op het probleem waar de GPS mee zat – niet terug kunnen).
Best-first
Alle mogelijke stappen worden onthouden, dus het geheugen wordt zwaar belast. Maar men
kan dus wel terug. De beste mogelijkheden worden eerst gecontroleerd, dan mindere
oplossing indien de beste oplossingen toch geen goed resultaat opleveren.
Hill-climbing wordt veel gebruikt, maar heeft veel bezwaren. Je kunt het wel toepassen als je
subdoelen uitzet en naar die doelen toewerkt (means-end analysis).
Voor de Gestalt-psychologen staat waarnemen gelijk aan denken. Een probleem los je op
door ernaar te kijken. Inzicht is dan ook het verkrijgen van een bruikbare
probleemrepresentatie. Een inzichtprobleem is het verkrijgen van dat inzicht moeilijk.
COLLEGE ? : RATIONALITEIT EN BESLISSEN
Bij de rationaliteit staat het denken voorop als zuivere bron van kennis – zelfs je zintuigen
kunnen je bedriegen. Pascal was het daar niet zo mee eens. Rationaliteit wordt gebiased
door emoties en onzekerheid.
Johnson-Laird stelt dat je modellen moet maken van de premises, waarop je vervolgens
conclusies maakt. Hoe meer modellen hoe meer fouten.
De regel van Bayes is een algoritme. Men gebruikt, volgens Simon, alleen maar bounded
heuristieken; heuristieken om rationaliteit te benaderen. De peterburgse paradox stelt dat
het rationeel best een goede keuze kan zijn dat partij A) iets doet, maar is het dan voor partij
B) ook slim?
COLLEGE ? : COMPREHENTIE
Een propositie is de kleinst mogelijke unit van een zin die op zichzelf kan staan, en toch kan
dienen als ‘waar / niet-waar’ stelling.
Experimentele methoden:
End-of-sentence probe recognition
Na het lezen van een zin wordt een probe gepresenteerd. De persoon moet aangeven of die
wel of niet voorkwam in de zin.
Cross-modal lexical decision tasks
De persoon luistert of leest iets en krijgt, op een willekeurig moment, een string aangeboden
en moet bepalen of het wel of geen geldig woord is. Dit berust op de associatie tussen
woorden en de reactietijd is een graadmeter voor de activatie van informatie in het brein.
Self-paced reading
Men meet de totale leestijd.
Eye-movement recording
Mensen gaan er vanuit dat de zinnen een tekst samenhangen (discourse model). Ze maken
zelf vaak referenties aan tussen zinnen.
Taalgebruik is het gebruiken van taal om iets teweeg te brengen. De locutie is dan het
gezegde, de illocutie de bedoeling en de perlocutie het effect van de bedoeling. Zodra de
spreker en de luisteraar hetzelfde bedoelen, is er sprake van common ground. Uit
onderzoek blijkt dat mensen vaak vergeten dat een andere spreker iets niet kan zien (en dus
geen common ground is), en er toch naar verwijzen.
COLLEGE ? : TAAL
Fonetiek gaat over de fysieke eigenschappen van klanken, terwijl fonologie gaat over de
mentale representatie van die klanken.
COLLEGE ? : SEMANTIC MEMORY
Het HERA-model (hemispheric encoding retrieval assymetry) stelt dat:
LPFC : verzorgt encoding
RPFC : verzorgt retrieval
COLLEGE ? : KLINISCHE NEUROPSYCHOLOGIE
Bij de klinische neuropsychologie besteedt men aandacht aan het diagnosticeren en
behandelen van cognitieve en emotionele stoornissen als gevolg van
hersendisfuncties. Wordt toegepast bij:
1] neuropsychologische stoornissen
2] psychiatrische stoornissen
3] ontwikkelingsstoornissen
4] veroudering en dementie
De toepassingen zijn divers:
Diagnose
1] differentiele diagnose tussen neurologische en psychologische problemen
2] neurologische diagnose (laesielocalisatie)
3] neuropsychologische diagnose
Behandeling
1] monitoren
2] advies
3] revalidatie
Expertise
1] objectiveren van cognitieve stoornissen
Onderzoek
1] syndroombenandering (selectie op syndroom)
2] leasiebenadering (selectie op leasie)
3] individuele benadering
Men maakt bij de diagnose gebruik van functiedifferentatie – men test een aantal
zaken oppervlakkig en gaat verder waar problemen blijken.
Trauma capitis is een hersenschudding. Delen van het brein schudden heen-en-weer
en raken beschadigd. Coma is mogelijk en wordt gemeten middels de glasgow scale.